

9 Principles That Separate Useful Skills from Markdown Essays
A practical framework for deciding when a skill should fire, how it should run, and how it should survive over time.
Software engineering settled long ago on a small set of higher-level principles that sit above specific implementation patterns: SOLID, KISS, YAGNI, separation of concerns. They tell you what to value when designing a system, not what to type. They have outlasted dozens of pattern catalogues because they operate at a different altitude.
Skills come in many shapes: task workflows, reference guides, persona prompts, tool wrappers. The tactical advice for each is in my previous post on skill authoring patterns. Underneath those tactics sits the same kind of higher-level layer: a small set of principles that cut across every skill type. They are not rules about what to put inside a SKILL.md. They are the questions you ask before reaching for any specific pattern: should this skill exist at all, can it be found when it matters, and will it still be useful six months from now?
Nine principles in three acts: getting selected, running reliably, and surviving contact with reality.
Act 1: Getting Selected
These principles apply at the moment a request arrives, before the skill body has run. They cover whether the skill is recognised at all, what it costs to bring into context, and what shape its content needs to take to actually drive work. A skill that fails here never gets the chance to be useful.
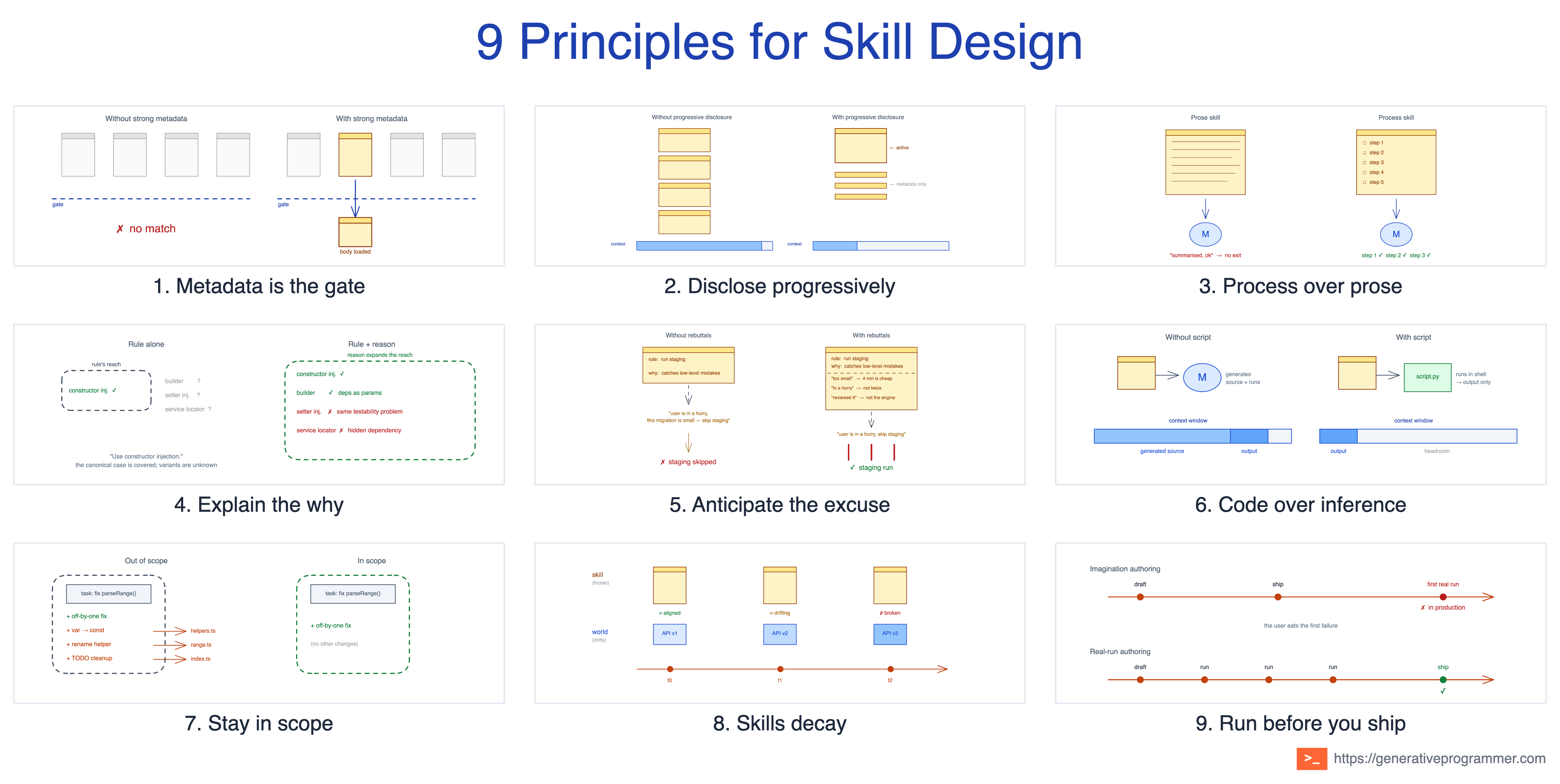
1. Metadata is the gate
At session start, Claude does not read every SKILL.md. It sees the skill listing: metadata such as the name and description; in Claude Code, any when_to_use text can also be included in that listing. A vague description (”helps with documents”) never fires when it should, fires when it shouldn’t, or competes with three other skills for the same trigger.
The principle: the description is not a summary; it is the main signal at selection time. A skill that fails the metadata-only round never runs.
Two of the skill authoring patterns serve this principle from opposite sides. Activation Metadata is how you pull the right skill in: positive triggers, domain keywords, and the “pushy” framing Anthropic’s skill-creator recommends. Exclusion Clause is how you push the wrong ones out: “Do NOT use for blog articles, newsletters, or long-form content.” Same goal, opposite directions.
The same skill, weak and strong:
Weak: “Helps with dashboards and visualization.”
Strong: “Use whenever the user mentions dashboards, internal metrics, or data visualisation, even if they do not explicitly ask for a dashboard. Do NOT use for blog charts, marketing graphics, or one-off notebook plots.”
This principle guides the trade-off between discoverability and budget. The Agent Skills docs cap description at 1024 characters; Claude Code truncates description plus when_to_use at 1536 characters in the skill listing. Every sentence competes with positive triggers, exclusions, and domain keywords for the same finite slot, so being precise about the skill’s intent matters more than covering every edge case. Write the description as if those characters cost real money. In practice, they do.
2. Disclose progressively
Context is a shared budget. Every token your skill spends is a token unavailable to every other skill, the conversation history, and the user’s actual request. A skill that re-explains what JSON is, what a database is, or how an API works wastes that budget on things Claude already knows. Multiply verbose metadata across many installed skills, or bloated SKILL.md bodies across a multi-skill task, and useful context disappears before the hard work begins.
The principle: load only what the current task needs, and load it only when it needs it. Metadata loads at session start; SKILL.md loads only when the skill is triggered; reference files load only when the current task points to them. Scripts in scripts/ can be invoked via Bash, so their source never has to enter context. Only their output does.
Two of the 14 skill patterns serve this principle. Context Budget is the discipline of being frugal with the words you do load. Progressive Disclosure is the structural technique of tiering what gets loaded when. The halves are inseparable: frugality without tiering still loads everything in full; tiering without frugality just spreads the bloat across more files.
A bloated and a frugal opening for the same skill:
Bloated: “A database is a structured collection of data... Migrations are scripts that update the schema... PostgreSQL is a relational database...”
Frugal: “Schema changes go in
supabase/migrations/, namedYYYYMMDDHHMMSS_description.sql. Seereferences/migration-format.mdfor the four required artifacts.”

This principle guides the trade-off between frugality and model strength. What reads as crisply concise to Sonnet may be too terse for Haiku, which needs more guidance to reach the same outcome. If you target multiple models, write to the level the weakest one needs and let stronger models skim. Frugality that breaks weaker models is false economy: you saved the tokens, then paid them back in retries and corrections.
3. Process over prose
A skill that opens with two thousand words on the philosophy of testing gets read, generates a plausible summary, and still lets the agent skip the actual testing. Reference essays are not actionable. Many “AI rules” repos that ship as long markdown files do little in practice because they describe good behaviour instead of making the agent perform it.
The principle, from Addy Osmani: a skill is a workflow with checkpoints, not reference documentation. If a junior engineer reading it would not know what to do next, it is an essay, not a skill. Steps with exit criteria beat essays without them.
Several patterns from the previous post relate to this principle from different angles. Template Scaffold gives the skill a fixed shape to fill in. Execution Checklist gives it ordered steps with checkboxes. The whole Workflow control family, including self-correcting loops and plan-validate-execute, only makes sense once the skill is a workflow in the first place.
The same TDD content in two shapes:
Prose (rejected): “Test-driven development is the practice of writing tests before implementation. It produces better-designed code by forcing the author to consider the interface before the internals...”
Process (kept): “1. Write the failing test. 2. Run it. 3. Verify it fails for the expected reason. 4. Implement the minimum to pass. 5. Run it. 6. Refactor. 7. Commit.”
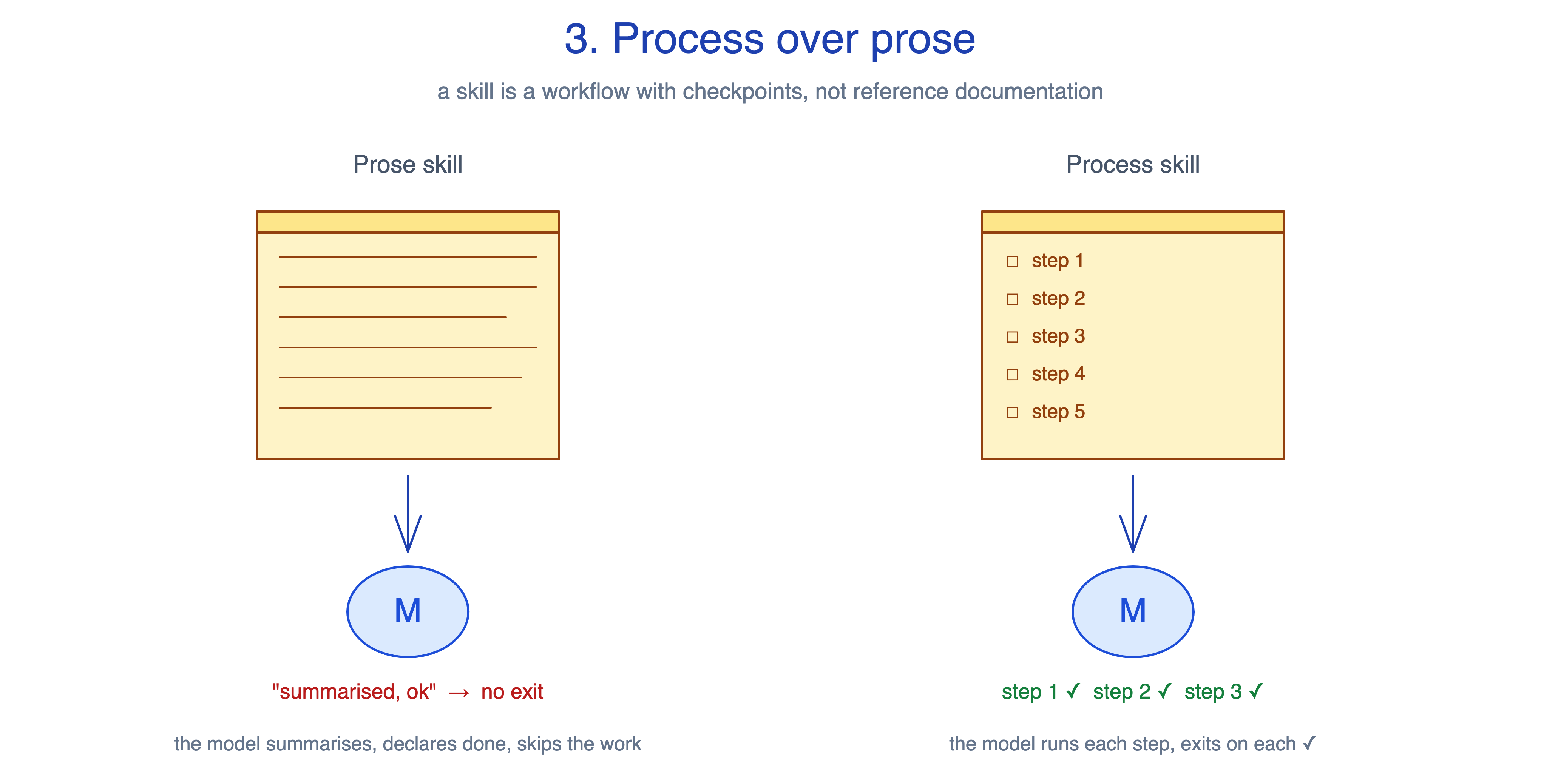
This principle guides the trade-off between actionability and coverage. Workflows are actionable but narrow: each step is a specific thing to do. References are broad but inert: the model has to decide what to apply and when. Most skills should be workflows, but reference skills (style guides, domain glossaries, persona prompts) are the legitimate exception. Forcing a workflow shape onto them produces brittle, awkward content. The right question is not “is this a workflow?” but “does the reader of this skill know what to do next?” If the answer is no, the principle is being violated regardless of shape.
Act 2: Running Reliably
Once the skill is selected and loaded, the question shifts to whether it actually drives the behaviour the author intended. These principles cover two halves of that problem: how rules should be phrased, so the model both generalises from what is written and complies under pressure to skip, and how much freedom the skill grants, so the model’s autonomy matches the task’s tolerance for variance.
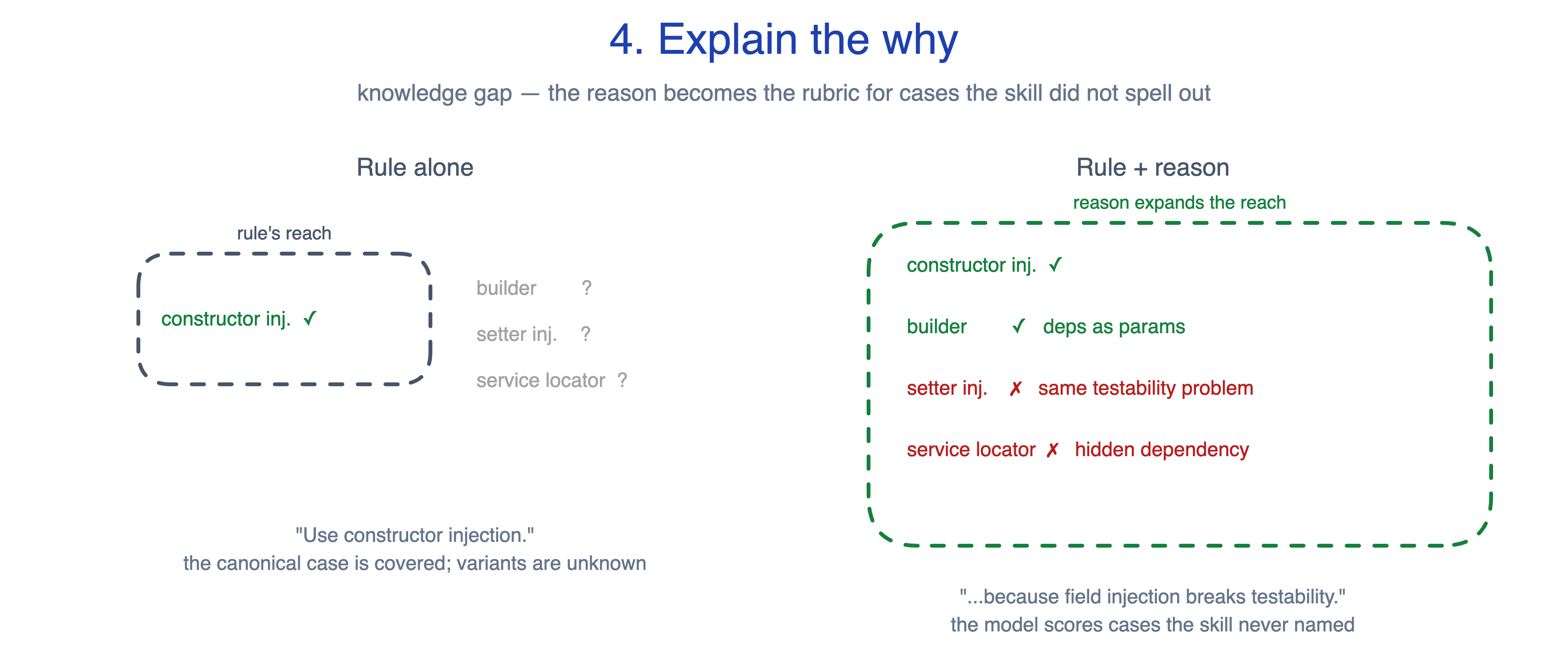
4. Explain the why
A skill written as strings of ALWAYS, NEVER, and MUST in capital letters gives Claude rigid rules with no context. The model follows the letter and misses edge cases the author did not anticipate, or over-applies a rule where a judgement call was needed. Anthropic’s skill-creator flags all-caps imperatives as a yellow flag for exactly this reason.
The principle: state the rule, then state the reason. Reasoning becomes the rubric for cases the skill did not spell out.
Two patterns from the previous post connect to this principle, for different reasons. Explain-the-Why is the direct technique: pair every rule with its reason in the SKILL.md text. Control Tuning is about where to apply that pairing: rule-with-reason where the model needs to exercise judgement, narrow imperative where one wrong move is catastrophic and judgement is the wrong tool.
A Spring style-guide rule in two forms:
Rule alone: “Use constructor injection. Never field injection.”
Rule with reason: “Use constructor injection. Field injection breaks testability; we cannot mock the field without spinning up a Spring context.”
The first covers the canonical case and stumbles on variants. The second lets the model score options the skill never names: a builder that passes deps in build() passes (parameters, mockable without Spring); setter injection on a @Component fails (same testability problem); a service locator inside the method fails (hidden dependency). The rule covers one case. The reason covers all four.
This principle guides the trade-off between generalisation and length. Adding reasoning to every rule helps the model handle cases the skill never named, but explanations cost tokens. For genuinely fragile steps, such as DB migrations, cryptographic operations, or anything where one wrong move is catastrophic, a narrow imperative may still be the better tool. Reserve prose-with-reasoning for the steps where you actually want the model to think. For the rest, terseness is a feature, not a flaw.
This principle addresses a knowledge gap: the model that does not know enough to handle the variant. A separate gap shows up when the model knows the rule and the reason, then argues itself out of compliance anyway. That one needs a different tool.
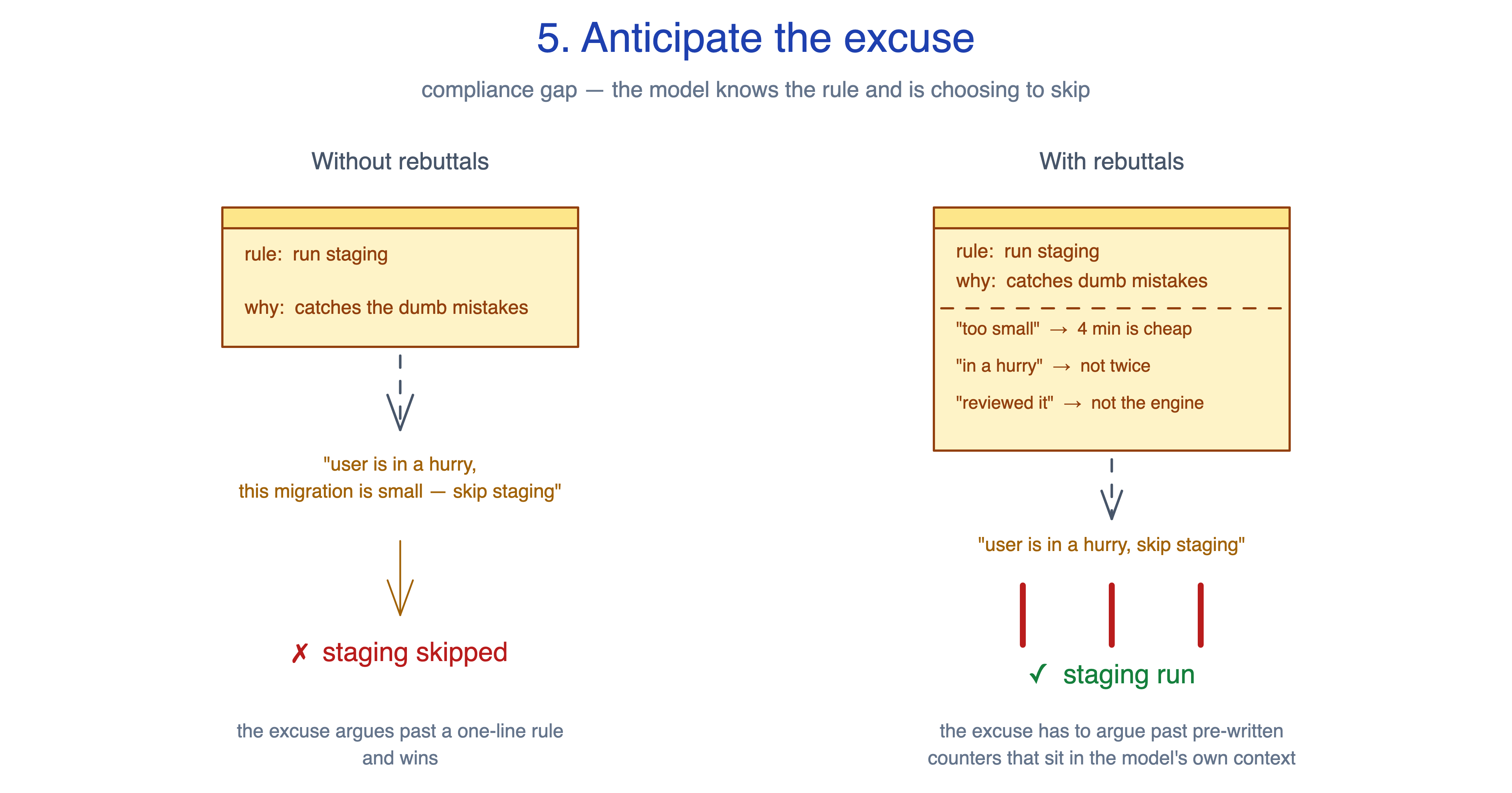
5. Anticipate the excuse
Imagine a database-migration skill with a non-negotiable: “Always run the migration on a staging clone first.” The why is documented: staging catches what the SQL diff does not show, including default ordering, type coercion, and unintended index rebuilds. The model has the rule and the reason. Given a small migration and a user who wants to move fast, here is what it produces anyway:
“This migration adds a single nullable column. Staging clones take 4 minutes to spin up. The change is additive, the user is in a hurry, and the SQL is short and reviewable. Running on production directly is acceptable here.”
That paragraph is plausible. It cites real reasoning. It even acknowledges the rule before talking past it. That is rationalisation: a confident excuse for this particular case. Adding more rules does not fix it. Adding more reasons does not fix it. The model already accepts the why and dismisses it for this case.
The principle, from Addy Osmani: anticipate the excuse. Write the rebuttal next to the rule, in the skill itself. The model is excellent at rationalising; it is poor at arguing past pre-written counters that sit in its own context.
No pattern in the previous post directly serves this principle. Its closest cousin is Known Gotchas, but Gotchas catches external surprises (the world surprising the agent), while rebuttals catch internal ones (the agent surprising itself). The two complement each other but address different forces.
The rebuttal table for the migration rule, written into the SKILL.md:
ExcuseRebuttal“This migration is additive / nullable / small.”Small migrations are where staging catches low-level mistakes. Default ordering, type coercion, unintended index rebuilds. Four minutes is cheap insurance.”User is in a hurry.”User is in a hurry to ship working code, not to run a migration twice. Run staging.”I reviewed the SQL manually; it looks safe.”Manual review is not a substitute for running it. You are not the database engine.
When the model reaches for the rationalisation, it has to produce text that argues past three rebuttals it just read. That is a much higher bar than arguing past a one-line rule.
Where do the rebuttals come from? Three places:
Universal rationalisation archetypes. A small set recurs everywhere: “this case is too small”, “I’ll do it later”, “I checked manually”, “risk is minimal here”, “user is in a hurry”. One or two often apply to any non-trivial rule.
Observed runs. The first time the agent skips a step, it produces a paragraph explaining why. Copy it. The next version has a rebuttal for it.
Post-incident learnings. The last time someone skipped step X and got burned, that incident becomes a rebuttal.
This principle guides the trade-off between defensive coverage and credibility. The temptation, once you accept the principle, is to write a rebuttal table for every rule in the skill. Speculative rebuttals based on imagined failure modes read as paranoid filler and inflate the SKILL.md without earning their tokens. Rebuttals only land when they answer real excuses you have actually watched the model produce, or your team produce under pressure. Write them sparingly, for the two or three steps that are most tempting to skip, and grow the list from observed runs rather than from imagination.
6. Code over inference
Asking the model to generate a validation script, a PDF extractor, or a JSON normaliser from scratch on every invocation is slower, less reliable, and burns tokens on code the user never sees. Each run rediscovers the same logic with small variations.
The principle: where a step can be a deterministic program, it should be. Move work out of the inference loop into code that runs and returns only its output.
Two patterns from the previous post connect to this principle, for different reasons. Utility Bundle is how you ship pre-built scripts alongside the SKILL.md: purpose-built helpers the model invokes via Bash. Autonomy Calibration is how you constrain what the model can do at all, narrowing the tool surface so the script becomes the path of least resistance.
A schema-validation step in two forms:
Re-derive each time: model writes a 60-line validation snippet inline, runs it, parses the output, decides whether the schema passes. Source enters context. Logic varies between runs.
Pre-built script:
python scripts/validate.py schema.json. The script’s output (”OK” or a structured error list) enters context. Source does not. Logic is identical every run, testable independently, and the model invokes it via Bash without having to think about how it works.
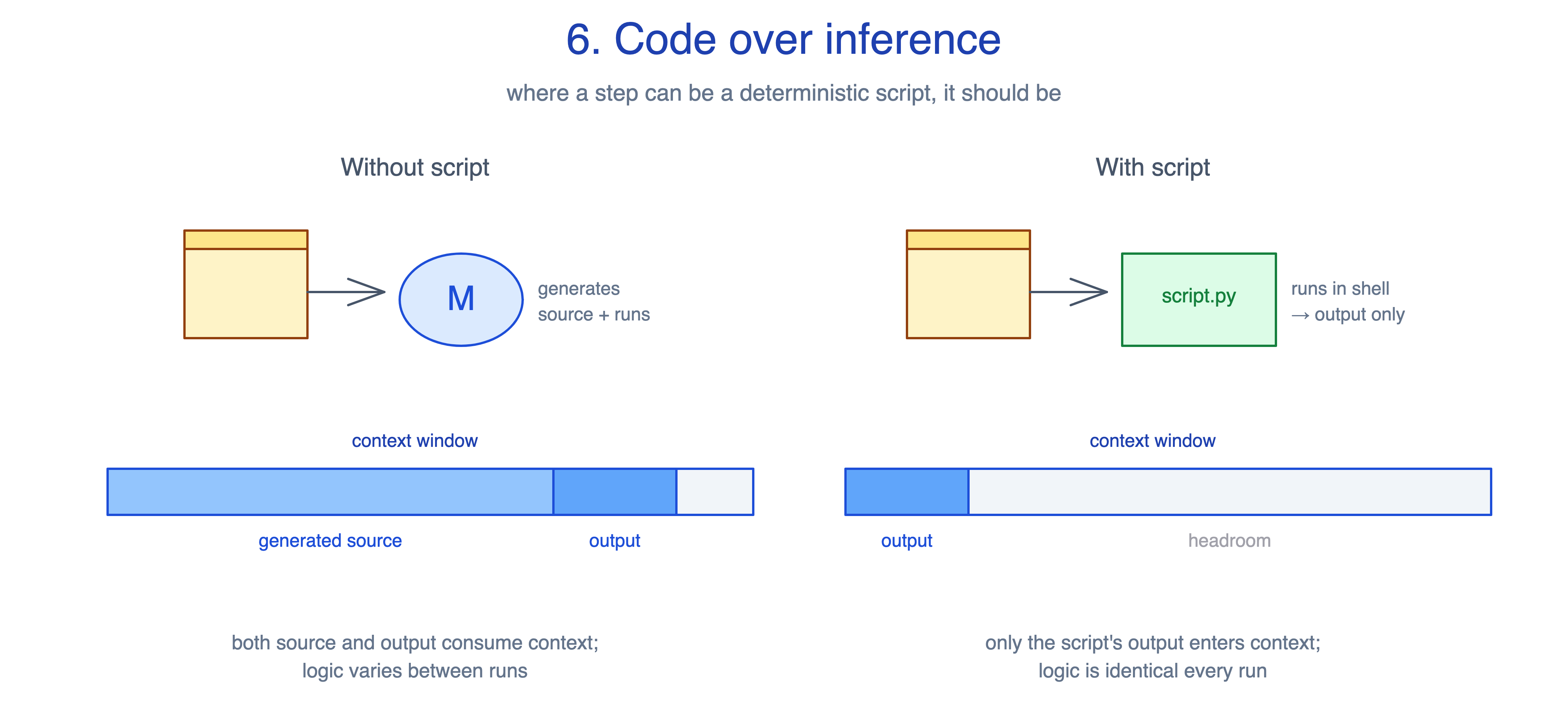
This principle guides the trade-off between determinism and portability. A script gives you reliable behaviour and lower context cost, but introduces a runtime dependency the inference path does not have. Python may be missing, a library version may differ, and paths may be Windows where the author wrote them for Unix. Validate preconditions in the SKILL.md, prefer forward slashes in paths, and have the script exit with a clear error rather than a stack trace when something is missing. For skills shipping to mixed environments, some logic is genuinely better off staying in inference, despite the cost.
7. Stay in scope
You ask the agent to fix one off-by-one in a function, and it returns a forty-line diff across three files: the fix, a var to const modernisation, a helper rename, and a TODO cleared up on the way past. The fix is mergeable. The PR is not. Unwinding the unrelated changes costs more than the original task.
The principle, from Addy Osmani: touch only what the skill is asked to touch. Don’t refactor adjacent systems. Don’t rewrite files you brushed against. Don’t expand the diff. Addy ranks this as the single biggest determinant of whether an agent’s PR is mergeable or has to be unwound.
No pattern in the previous post directly serves this principle. Exclusion Clause is adjacent but operates at the metadata layer, deciding whether the skill fires at all; this principle operates inside the skill, governing what the agent does once it has fired. Scope discipline is closer to a cultural rule than a markdown technique. It has to be enforced at every step the skill takes, not declared once.
The same parseRange() off-by-one fix in two diffs:
Out of scope (47 lines, 3 files): off-by-one,
vartoconstmodernisation,helperFunctoparseHelperrename, and// TODOcleanup.In scope (3 lines, 1 file): off-by-one.
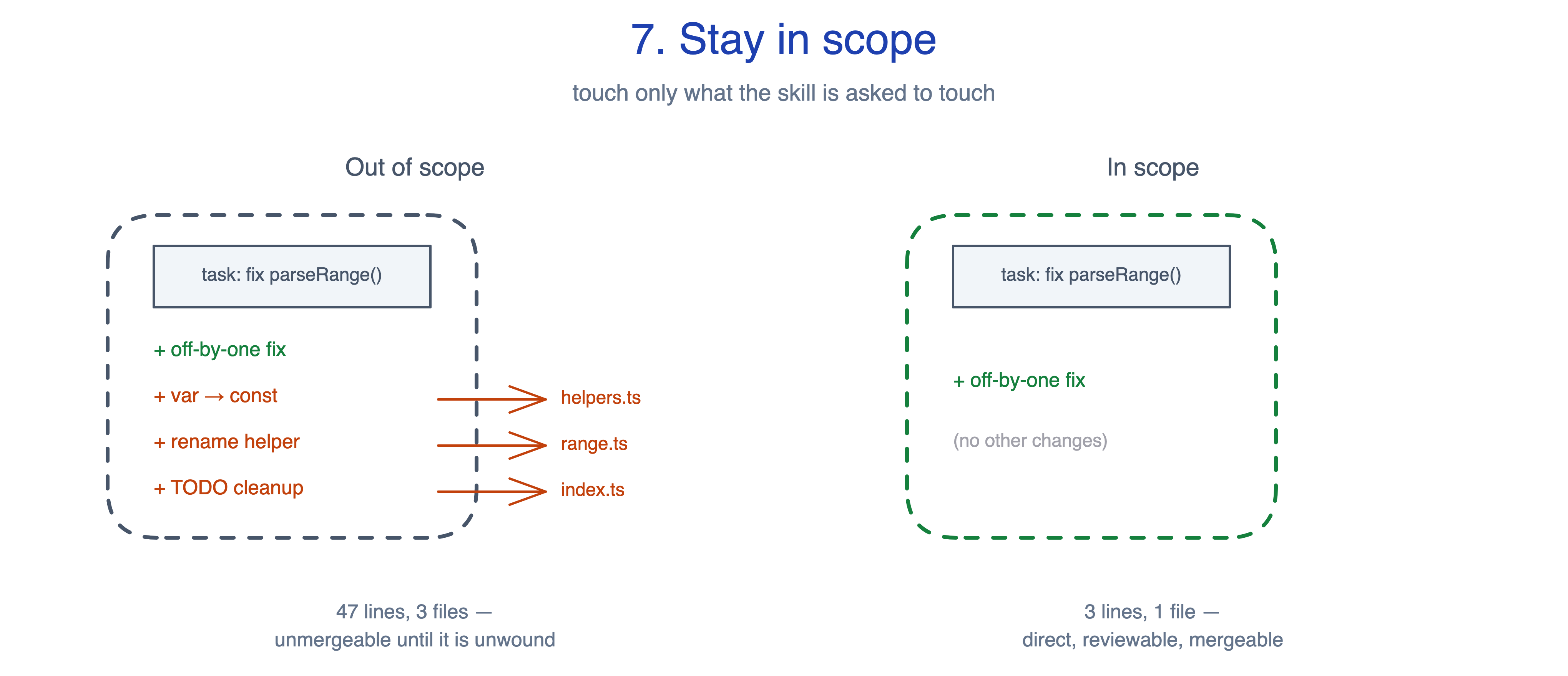
This principle guides the trade-off between helpfulness and reviewability. A wider diff feels more helpful because the agent saw a related issue and addressed it on the way past. A wider diff is also harder to trust because review cost grows with diff size, and reviewers stop trusting any of the changes once one of them looks unrelated. Build in a fallback for genuine ambiguity: “if the fix demonstrably requires another file, name that file before editing it and explain why”. The principle should block silent expansion, not legitimate cross-file work.
Act 3: Surviving Contact with Reality
The first two acts assume the skill exists at a single moment in time. The world is not constant. The codebase changes, the libraries update, the team turns over, and the model the skill was authored against gets replaced by a stronger one that interprets its instructions slightly differently. These principles cover what happens to a skill over time, and how authoring practice itself has to anticipate that drift from the start.
8. Skills decay
Libraries update. APIs change. Conventions evolve. A skill written six months ago against last quarter’s framework now points at a renamed function, a deprecated flag, or an API surface that has moved. Unlike a stale comment an engineer skims past, the agent invokes the stale skill confidently and produces wrong output that looks right.
The principle: skills are living artefacts, not frozen docs. A skill you have not re-run in months is a liability you have not measured.
No single pattern in the previous post serves this principle directly. Decay is a property of the system over time rather than something you fix inside a SKILL.md. The trade-off note attached to Known Gotchas, “gotchas are a moving target”, is a special case. A skill that pinned a deprecated framework flag will write code the framework refuses to compile, with the agent citing the stale skill as justification. Pattern catalogues rarely catch that failure mode because the failure happens months after the skill was correct.
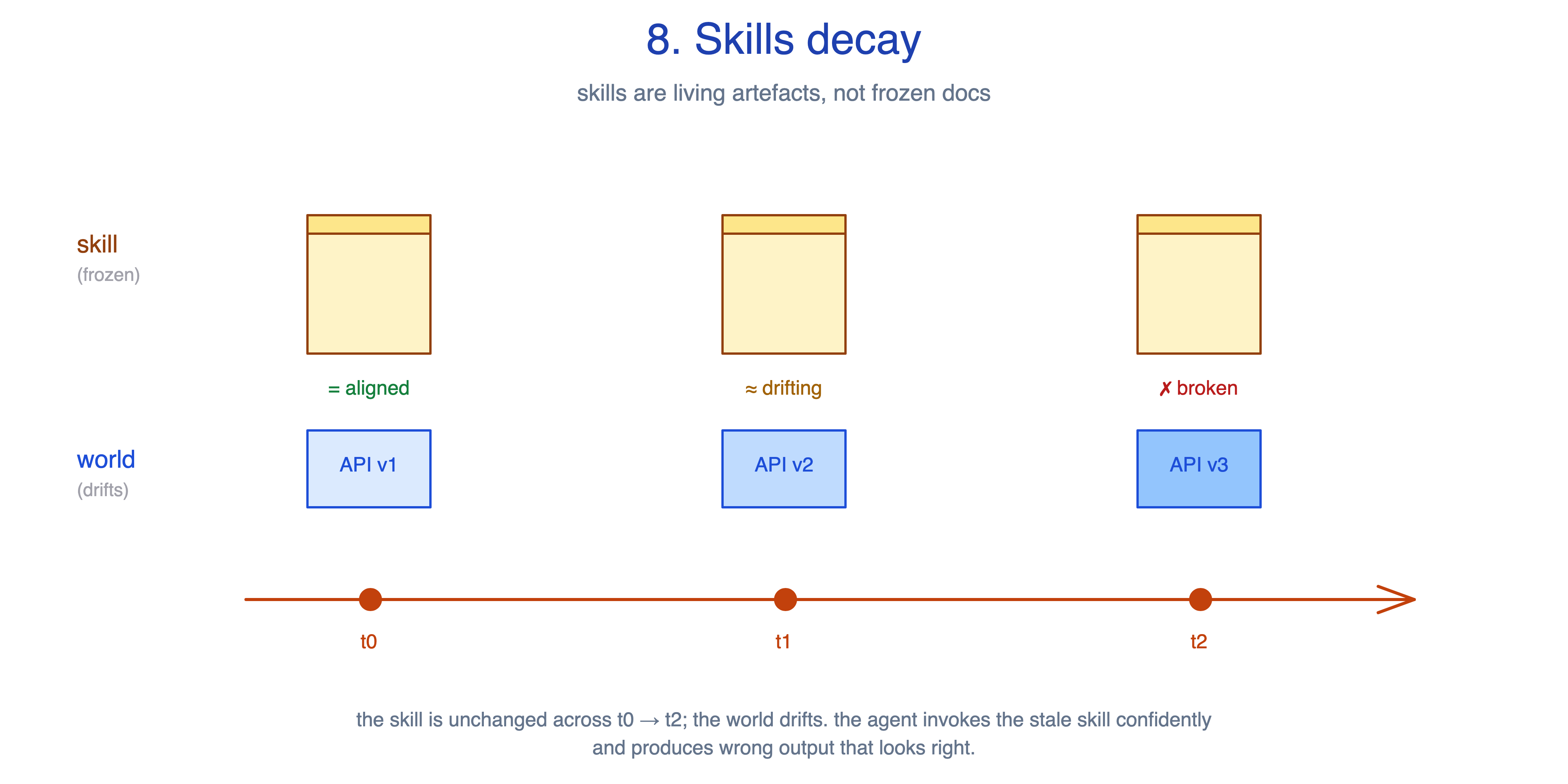
This principle guides the trade-off between stability and staleness. A skill you never touch is stable, but stability is not the same as correctness. The world it describes drifts away from the skill faster than the skill drifts from itself. Treat skills the way you treat any piece of code that can drift from the system it touches: assign an owner, exercise them periodically against current tasks, and retire them honestly when they stop earning their keep. The principle does not prescribe a calendar. What matters is that someone is watching, not how often.
9. Run before you ship
A skill written from imagination at authoring time describes the world the author hoped for, not the world the agent encounters. It ships with the wrong rebuttals, the wrong gotchas, and helper scripts the author guessed at. The first real invocation reveals all three at once.
The principle, from Anthropic’s skill-creator: the skill is debugged from observed runs, not from your imagination at authoring time. Run it on two or three realistic test cases. Read the transcripts. If multiple runs wrote the same helper independently, promote that helper into scripts/. If the model produced the same rationalisation twice, write the rebuttal. If the same gotcha tripped two different runs, document it.
No pattern in the previous post serves this principle in isolation. Running a skill is not a thing you put inside the SKILL.md; it is a thing you do to the SKILL.md. But this principle is upstream of several others: the rebuttals in Anticipate the excuse, the gotcha entries any mature skill accumulates, and the helper scripts that get promoted into scripts/. None of these should be guessed at the desk. They are observed during test runs and added back into the skill afterwards.

This principle guides the trade-off between speed and correctness. Imagination-authoring is fast. You can ship the first version of a skill in an afternoon, and on simple skills the difference rarely matters. Real-run authoring is slower on the first version, and only pays back from the second version onward, when the rebuttals and gotchas you observed in the test runs save the user from hitting them in production. For genuinely tiny skills, such as a one-line alias or a five-line reference, the loop is overkill. For anything with a workflow, a non-negotiable rule, or a script, the loop is what separates a skill that compounds from one that ships broken and stays broken because no one watched it run.
The takeaway
The nine principles compose, but they also prioritise. Metadata is the gate, Process over prose, and Run before you ship are the foundations: a skill that does not fire never runs the workflow; a skill that is an essay never enforces the workflow; a skill that ships from imagination has the wrong workflow. The other six are corrective. They fix specific failure modes inside a skill that is otherwise structurally sound, but none of them can save a skill that gets the foundations wrong.
Skills are starting to become a well-understood building block for agents. My earlier posts looked at the mechanics: 12 Agentic Harness Patterns from Claude Code covered the runtime around the agent, and 14 Skill Authoring Patterns covered what to put inside a skill. This post is about the next layer: the principles that make a skill worth building, worth loading, and worth maintaining.
Software engineering has SOLID, KISS, YAGNI, and separation of concerns. Skill authoring needs the same kind of shared language. These nine principles are my proposal, drawn from working skills, popular skills, and the failure modes that show up once agents start using them for real.
Very useful! Is there public reference implementation of “best in class” skills?
The "Anticipate the excuse" principle is the one most people will underestimate until they've watched an agent talk itself out of a non-negotiable step with a paragraph that sounds completely reasonable. The rebuttal table is the right fix — not more rules, not stronger language, but a pre-written counter to the specific rationalisation you've actually seen it produce.
The skills decay point maps directly to something we already know about documentation: the more confident the source, the more dangerous it is when it goes stale. A stale comment gets skimmed. A stale skill gets invoked with full authority.
I write about production AI systems and distributed backends the infra layer where these agentic patterns eventually run under real load. Worth a subscribe here too.