

The Missing Quality Layer for AI Coding Agents
As coding agents get better at writing code, the next challenge is proving the code is safe to merge.
There is a growing trend with more experienced teams adopting coding agents. They are moving past the first-order question of whether Claude Code, Cursor, Codex, or similar tools can write useful code. The answer is increasingly yes. The harder question is what has to exist around those agents before teams can trust the code they produce.
That shift matters because coding agents make the first draft cheaper, but they do not make quality automatic. A green build is still a narrow signal. It tells you the code compiled, the formatter ran, and the existing tests passed. It does not tell you whether the agent preserved the product rule, whether a generated test asserts real behavior, whether a refactor crossed an architectural boundary, or whether an installed MCP server had access to credentials it should never see.
The trend I’m seeing is the emergence of a quality layer around agentic coding. It sits between the agent and the pull request. Its job is to give the agent useful feedback while it works, constrain risky changes before they grow, and leave enough evidence behind for humans to understand what happened later.
This is where Birgitta Böckeler’s work on maintainability sensors for coding agents is useful. She describes how agents can quietly compound inadvertent technical debt when they lack the right feedback signals. OpenAI’s Codex engineering team describes a similar discipline as harness engineering: custom checks, architectural constraints, and repository-level quality signals become part of the environment agents work inside.
I think of this as the agent quality layer. It has two jobs: catch mistakes before they become review work, and prove where the work came from after it lands.
This post covers five practical controls for that layer. Each one names a failure mode, the control that reduces it, and tools or techniques teams can use today.
1. Feedback Sensors
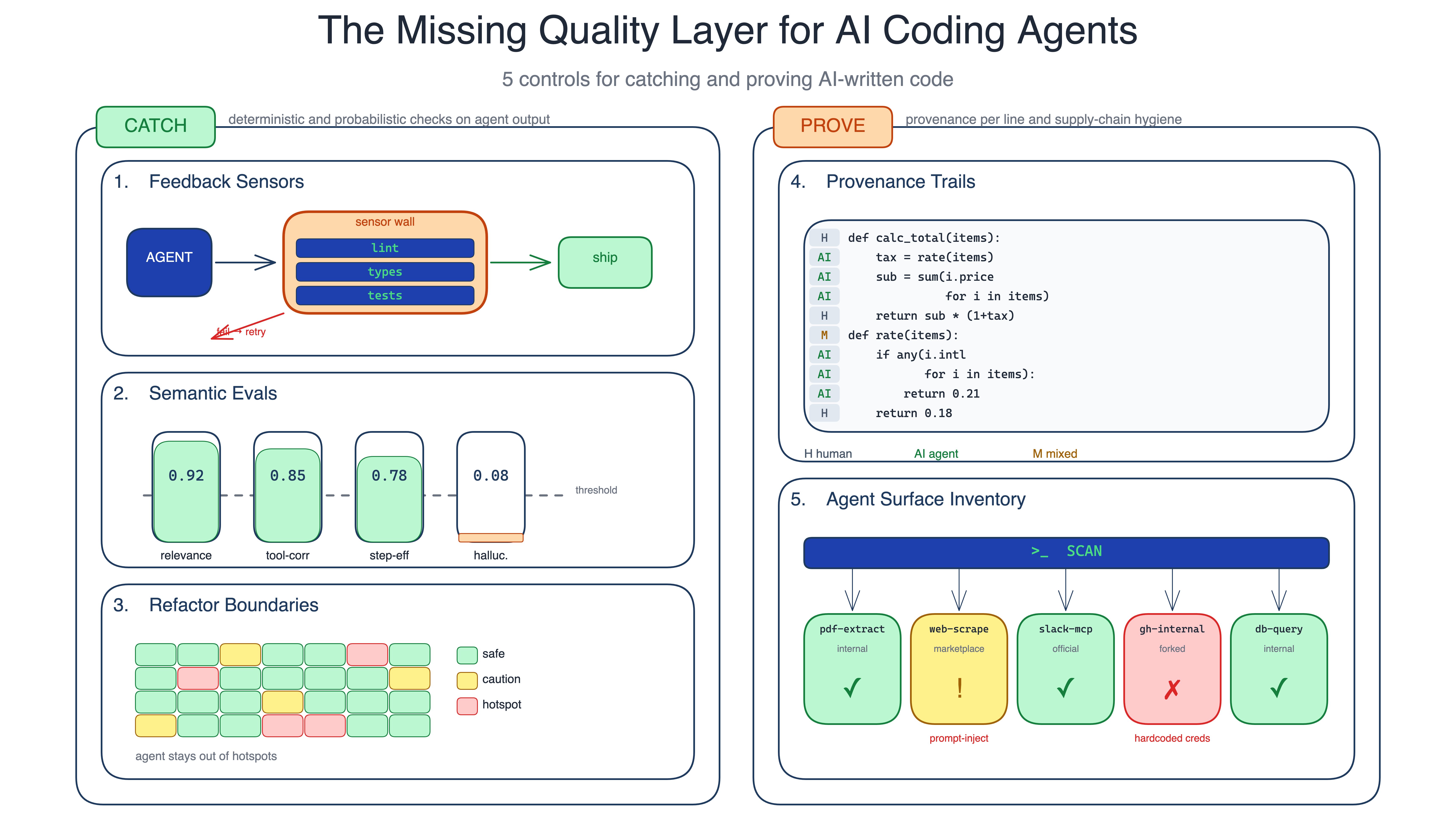
A coding agent that produces a diff without compiler feedback turns the human reviewer into the first quality gate. Reviewers end up seeing type errors, broken builds, failing tests, formatting noise, and simple lint violations that should never leave the session.
Feedback sensors wire deterministic checks directly into the agent’s loop. Compilers, linters, type checkers, structural tests, and focused test suites run during the session. When a check fails, the agent sees the output and tries again before the human reviews the diff.
The useful detail is not only running the check, but giving the agent failure messages it can act on. Böckeler describes embedding self-correction guidance inside lint errors, for example through a custom ESLint formatter. The agent sees what failed, why it failed, and how the team expects the fix to look. OpenAI’s Codex team describes the same move: custom lint messages carry remediation guidance into the agent context at the point of failure.
Related tools and techniques.
Start with the compiler, type checker, project-specific lint rules, focused test commands, and build validation for the changed module.
Add custom lint formatters for recurring agent mistakes.
Use mutation testing tools such as cargo-mutants when passing tests is not enough evidence that tests assert meaningful behavior.
Use fuzzers such as WuppieFuzz for API and input-space testing where examples miss edge cases.
In Claude Code or Cursor, run fast checks through hooks, tasks, or a reviewer agent so they happen consistently.
When to use. Any team using coding agents on production code. Start with fast checks in the session: lint, types, focused tests, and build validation for the changed module.
The main trade-off. Slow sensors choke the loop. Keep fast checks in-session, and push slower checks such as mutation testing, fuzzing, and modularity reviews into CI, scheduled runs, or explicit review passes.
2. Semantic Evals
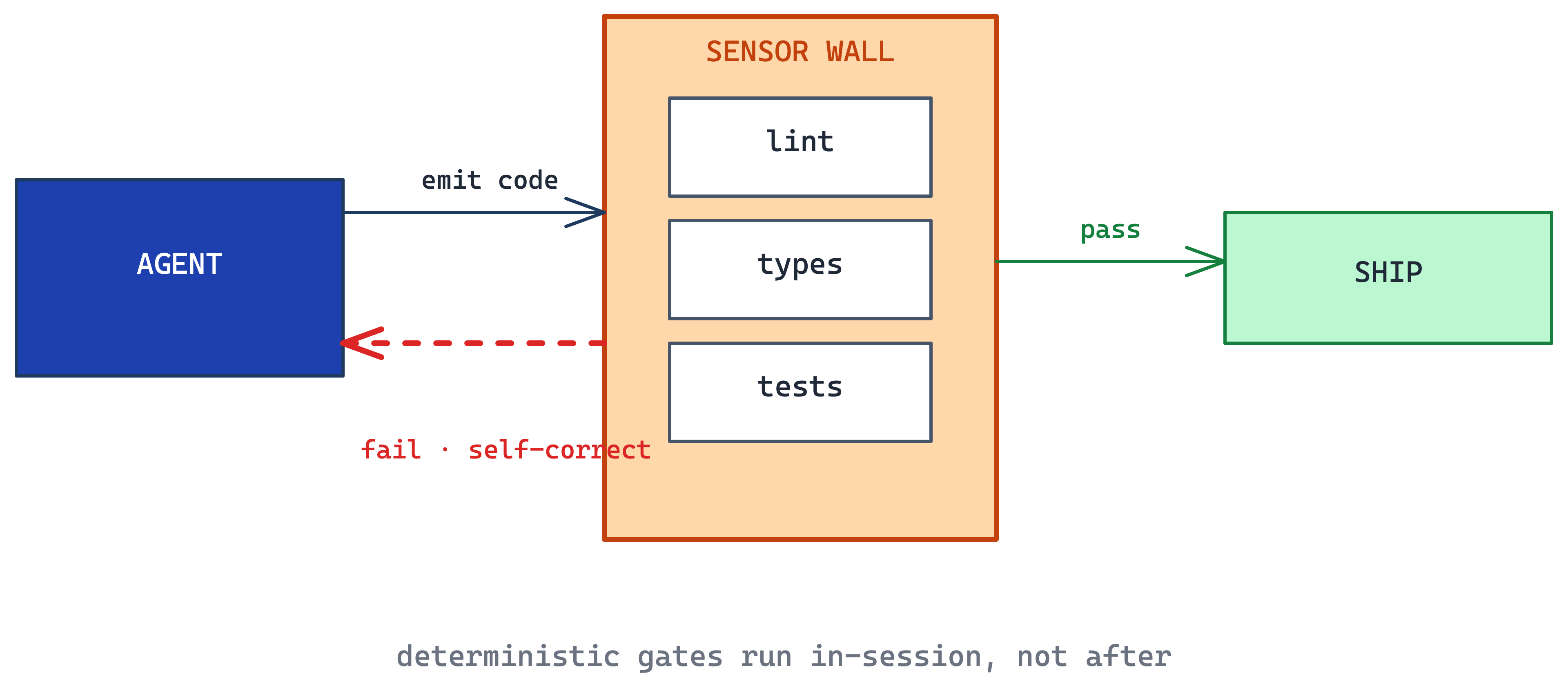
Deterministic sensors catch mechanical failures, but they do not catch code that compiles, passes tests, and still does the wrong thing. This is common with agent-generated tests, policy logic, tool-use workflows, data transformations, and customer-facing answers where correctness depends on meaning rather than syntax.
Semantic evals add probabilistic checks that score output against expected behavior. A semantic eval might verify that a generated test fails for the right reason, that an agent used the correct tool sequence, that a response stayed grounded in retrieved evidence, or that a policy decision matches known examples.
The eval suite should live near the test suite, but it evaluates agent behavior and generated output rather than only deterministic function results.
Related tools and techniques.
Keep a small golden set of examples for behavior the agent must preserve.
Use DeepEval or a similar framework for tool-use, hallucination, answer-quality, and custom use-case checks.
Use LLM-as-judge only with reviewed examples, clear thresholds, and failure review.
Consider approaches such as semantic entropy when you need to flag fluent answers that may still be uncertain.
For code structure, use LLM-assisted analyzers such as Vlad Khononov’s modularity plugin to inspect coupling, abstraction boundaries, and semantic duplication.
Combine semantic review with deterministic rules. Do not make model judgment the only gate.
When to use. Agent-generated logic that affects business decisions, customer workflows, policy interpretation, migrations, or domains where correctness is hard to verify by reading.
The main trade-off. Semantic eval is itself probabilistic. False positives train teams to ignore alerts, while false negatives create a false sense of safety. Treat the eval suite as production code: review examples, tune thresholds, and track failures over time.
3. Refactor Boundaries
Coding agents can rewrite code faster than humans can review it. That speed is useful in clean modules and risky in old, high-churn parts of the codebase. A 2,000-line god class with twelve years of business logic is exactly the kind of structure an agent may confidently refactor, and exactly the kind of structure where a refactor can delete behavior nobody documented.
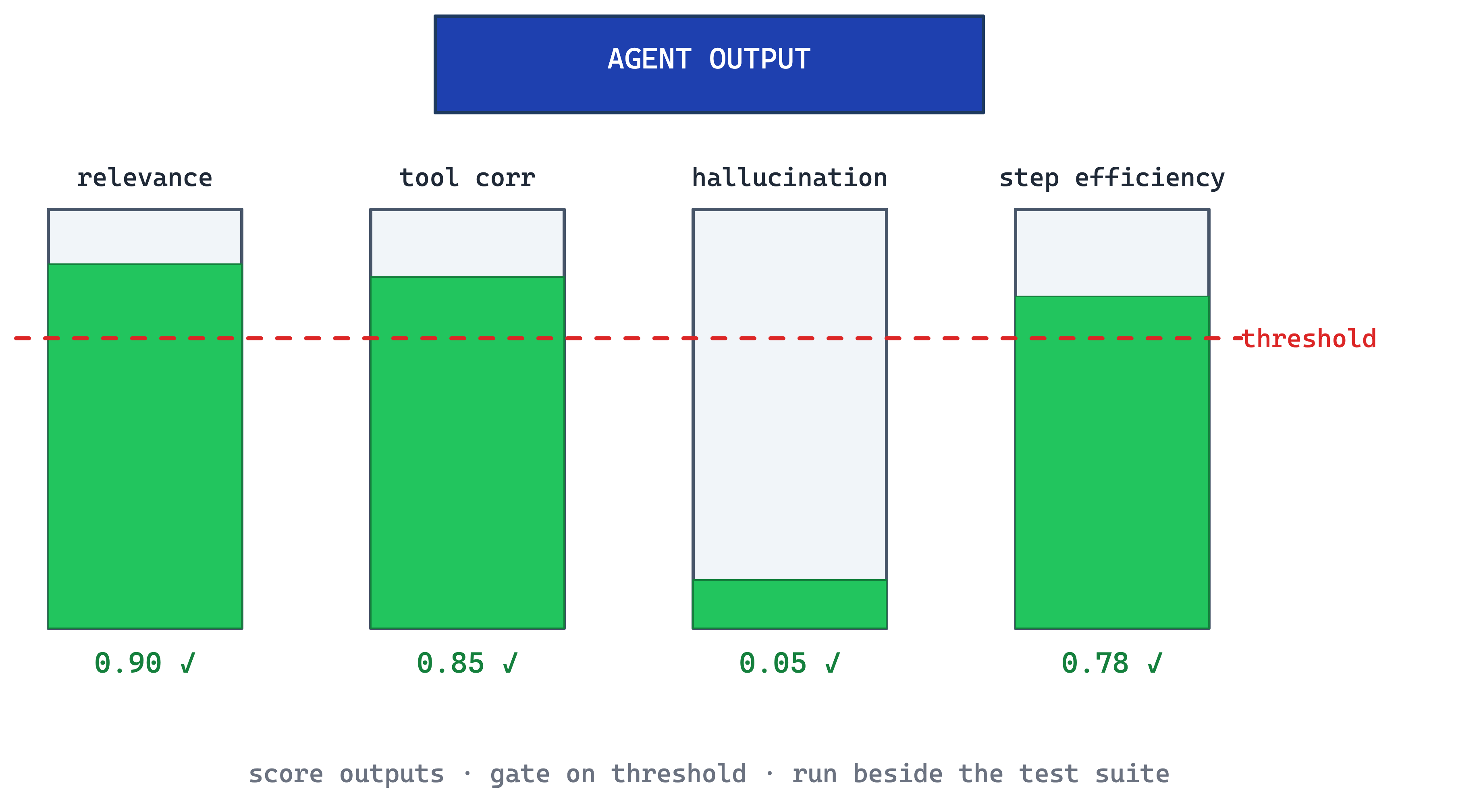
Refactor boundaries classify the codebase by complexity, churn, ownership, and architectural risk before the agent starts rewriting. The output is a practical map: green zones for routine edits, yellow zones for scoped changes with focused tests, and red zones where large rewrites need human design first.
The point is not to block agents from refactoring. The point is to make safe refactoring cheaper than unconstrained rewriting.
Related tools and techniques.
Use CodeScene or a similar tool to combine static complexity metrics with version-control history and surface hotspots.
Mark high-risk files with CODEOWNERS, required reviewers, or path-based approval rules.
Use dependency-cruiser, ArchUnit, or Spring Modulith to enforce module boundaries and dependency direction.
Track a lightweight quality score per domain or module, especially in areas where agents make repeated changes.
Let agents make small cleanup PRs in green zones, but require a human design step before broad rewrites in red zones.
OpenAI’s Codex team applies this shape at scale by splitting business domains into fixed layers, tracking per-domain quality, and enforcing architectural boundaries with custom linters. That is the practical lesson: constraints make speed safer.
When to use. Any codebase where not every file is equally safe for an agent to touch. This usually starts once the codebase has legacy modules, high-churn hotspots, or undocumented domain rules.
The main trade-off. Hotspot maps need calibration. The line between safe and unsafe is judgment, not a constant, so teams should revisit thresholds as the codebase and agent capabilities change.
4. Provenance Trails
Traditional attribution assumes a human wrote the code. In an AI-assisted codebase, that assumption breaks down because a line may come from a human, an agent, or a mixed session where the human accepted, edited, and committed generated output. git blame shows who committed the line, but not which model, prompt, skill, or tool contributed to it.
Provenance trails capture attribution for AI-generated changes with enough detail to reconstruct what happened later. At minimum, this means recording whether a change was human-authored, AI-authored, mixed, or unknown. A more useful trace also records the agent, model, prompt or task description, tool calls, installed skills, and the point where a human took over.
The practical benefit is not only auditability. Humans and agents can query the original intent behind a block of code before changing it again.
Related tools and techniques.
Start with low-friction provenance in PR metadata: agent used, model, prompt summary, tool summary, and generated files.
Use Git AI when you need commit-level or line-level tracking of AI-generated code.
Track attribution with Git Notes or another side channel when you do not want provenance metadata in source files.
Watch Agent Trace, Cursor’s proposed format for AI code attribution across version-control systems.
Move from PR-level metadata to line-level attribution when audits, compliance, or long-lived generated code justify the cost.

When to use. Teams that need to audit AI contributions, debug generated code, or reconstruct why a piece of code exists months after it was merged.
The main trade-off. Attribution metadata grows with the codebase. Storage, query cost, and developer workflow friction are real, so the harness should record provenance automatically instead of relying on manual discipline.
5. Agent Surface Inventory
The agent’s surface area is no longer just the model. It includes skills installed in the plugin directory, MCP servers it can call, marketplaces it pulls from, and credentials it can reach. Each one is a dependency, and some of them have more access than a library imported into application code.
Agent surface inventory treats that surface like a software supply chain. The team keeps an inventory of installed skills, plugins, MCP servers, versions, owners, permissions, credential scopes, and source locations. New entries go through review before they become part of the approved harness, and existing entries are scanned for risky flows.
This is the same basic discipline teams already apply to package dependencies: know what is installed, know who owns it, pin versions where possible, and review anything that gets access to internal systems.
Related tools and techniques.
Maintain an allowlist of approved skills, plugins, and MCP servers.
Version-pin what is installed.
Use least-privilege credentials for MCP servers.
Scan local agent directories in CI or on developer machines.
Use Snyk Agent Scan to inspect MCP servers, skills, and plugins for risks such as prompt injection, tool poisoning, toxic flows, hardcoded secrets, and unsafe credential handling.
Use MITRE ATLAS as a shared vocabulary for threat modeling AI systems and agentic attack paths.
Treat marketplace installs the same way you treat npm, Maven, or container dependencies: reviewed, versioned, and owned.
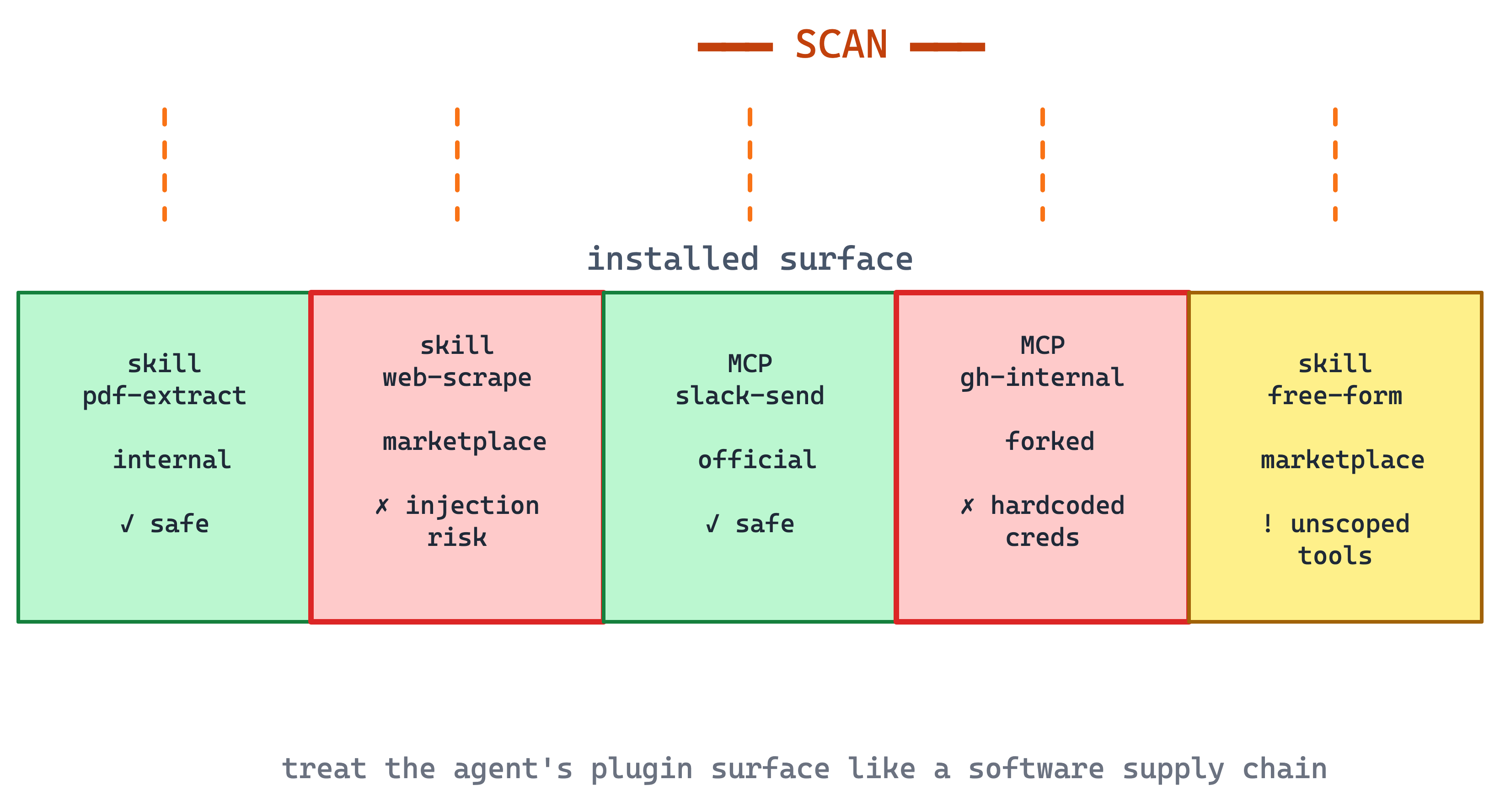
When to use. Any team that allows skills, plugins, or MCP servers from sources the team did not author, or any team where agents can reach internal systems through credentials.
The main trade-off. Scanners produce noise. Validate signal quality and false-positive rates in the team’s own environment before scan results become a hard gate, otherwise developers learn to ignore the output.
The takeaway
AI coding agents make first drafts cheaper, but trust still comes from engineering controls: fast feedback, semantic evals, refactor boundaries, provenance, and agent-surface inventory.
The Thoughtworks Technology Radar is a useful signal that these practices are becoming normal engineering hygiene, not a separate AI ritual. The tools will change, but the quality layer will remain.
This builds on the foundation I covered in How Teams Scale Claude Code Across Monorepos and Large Codebases: context, maps, skills, hooks, and shared harnesses. Once agents can find the right code, the next question is whether teams can trust what they change.