

Key Generative AI Concepts Every Software Developer Should Know
Understand These Now—Or Fall Behind in the Next Wave of Software Innovation
Every 5–10 years, the software industry experiences a paradigm shift that redefines how we build systems. We've seen this with object-oriented programming and design patterns, unit testing, microservices, containers and orchestration (Kubernetes), and cloud-native architectures. Each wave brings new terminology. Understanding these terms—even if you’re not using them daily—helps you learn faster, communicate better, and stay relevant.
Generative AI is the latest shift. This article introduces 10 foundational GenAI concepts that have become critical to understanding the technology and building on top of it.
1. Transformer Architecture
The path to today's ChatGPT began around 2014, when the dominant approach to language processing was sequence-to-sequence models. These models, pioneered by researchers at Google in their paper "Sequence to Sequence Learning with Neural Networks", worked like a pipeline with two main parts: an encoder that processed input text word by word, and a decoder that generated output text. These models would compress an entire sentence into a single fixed-length vector before generating a response, creating a major bottleneck where longer texts lost substantial information.

In 2015, researchers proposed a better solution called "attention" in the paper "Neural Machine Translation by Jointly Learning to Align and Translate". Instead of forcing all information through one vector, attention allowed the decoder to "look back" at different parts of the input when generating each output word. This was like giving the model the ability to focus on relevant parts of the input as needed, similar to how humans might re-read specific sentences when composing a response.
The real breakthrough came in 2017 with the paper "Attention Is All You Need", which introduced the Transformer architecture. What made Transformers revolutionary was that they:
Processed all words in parallel rather than one-by-one (massively speeding up training)
Used a sophisticated "self-attention" mechanism that let each word directly relate to every other word
In 2018, OpenAI built on this by creating GPT (Generative Pre-trained Transformer) in their paper "Improving Language Understanding by Generative Pre-Training", which used just the decoder portion of the Transformer architecture. The key innovation was pre-training on massive amounts of text data before fine-tuning for specific tasks. The book Prompt Engineering for LLMs explores this evolution in greater detail.
2. Agentic Systems
At its core, an agentic system uses an AI model (typically an LLM) to autonomously perform tasks by making decisions and taking actions to achieve specific goals. Unlike simple prompt-response interactions, these systems can reason, plan, use tools, and adapt their approach as they work toward completing objectives.
Rather than defining agents in binary terms (agent vs. not-agent), it's more useful to think of agentic behavior as a continuum—from rule-following assistants to fully autonomous problem-solvers. As Anthropic folks suggest, different systems can be agentic to different degrees depending on their capabilities and autonomy level.
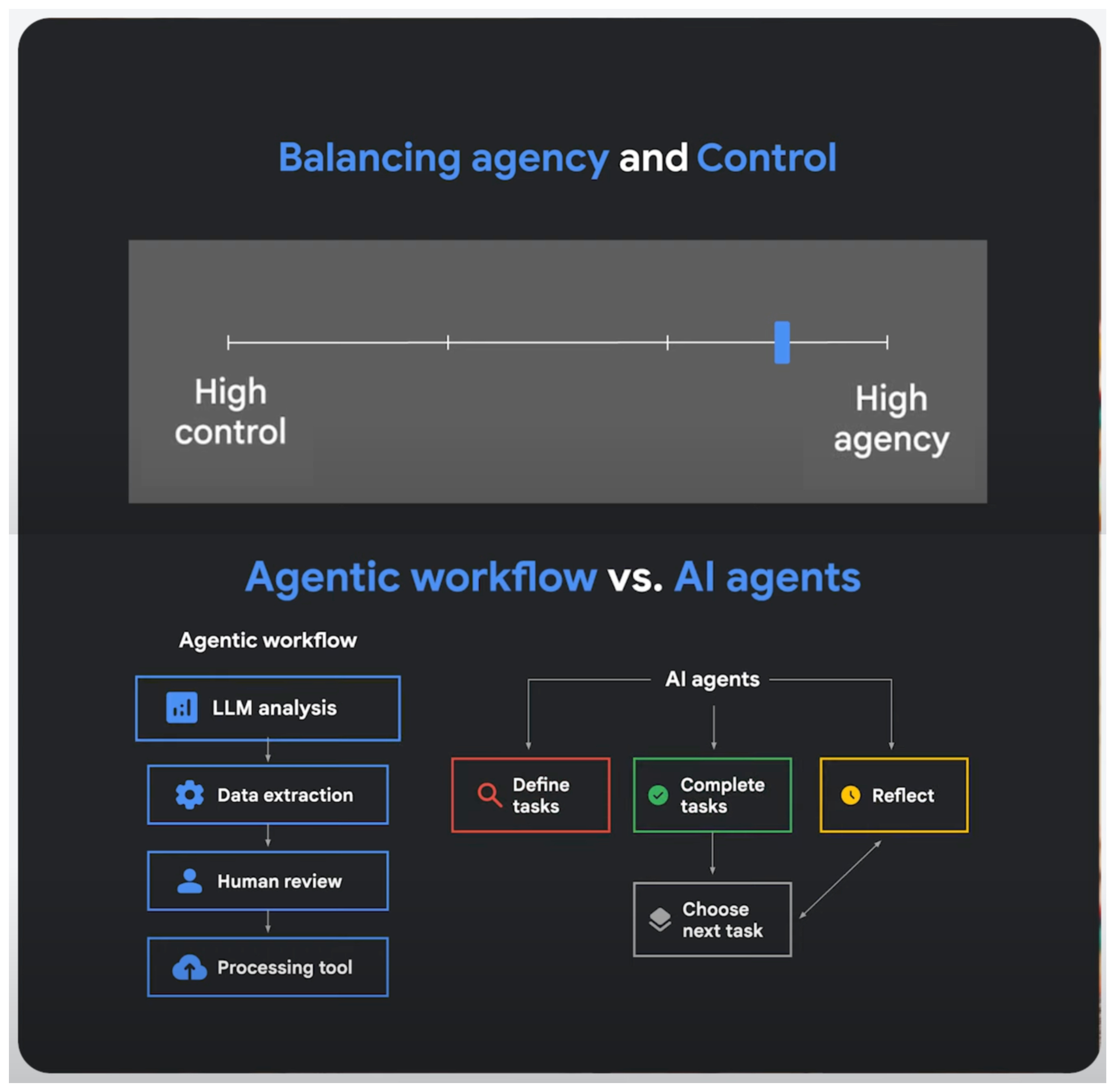
The agentic spectrum expands to:
Agentic Workflows sit at the more controlled end of the spectrum. These involve an LLM making limited decisions within a structured process, where the path to completion is largely predefined. For example, an invoice processing system might use AI to extract data, classify documents, and prepare them for human review—following a specific series of steps with limited autonomy.
Autonomous Agents represent the high end of the spectrum, with the ability to determine their own goals, subtasks, tools, and execution strategies with minimal human guidance. These agents might employ complex planning, self-reflection, and error correction to accomplish broadly defined objectives like "research a topic and write a comprehensive report" or "plan a vacation based on preferences."
For software engineers, the important consideration isn't whether something is truly an agent, but rather what degree of autonomy makes sense for your particular application. Many business problems benefit from the more controlled approach of agentic workflows, while more complex exploratory tasks might call for greater autonomy. See a precise coverage of 'agentic' in this video by the Google Cloud DevRel team.
3. Non-Determinism
Traditional software systems are deterministic—given the same inputs, they produce the same outputs every time. In contrast, generative AI introduces fundamentally non-deterministic behavior, where identical prompts can produce different responses even with the same parameters.

This non-determinism comes from several sources:
Sampling methods like temperature and top-p that intentionally introduce randomness
Context-sensitivity where subtle changes in context lead to different interpretations
Training variation that causes models to develop different "paths" of reasoning
Consider an AI agent tasked with researching a topic. We cannot predict in advance which tools it will call, in what order it will use them, how many iterations of research it will perform, or when it will decide the task is complete. One execution might involve three web searches followed by summarization, while another execution with the identical starting point might involve dozens of searches, calls to analysis tools, and multiple refinement steps.
This runtime non-determinism creates a fundamentally different software architecture. Rather than defining explicit sequences of operations, engineers must create environments where agents can operate safely within boundaries. These boundaries typically include:
Maximum execution time or token limits
Caps on the number of tool calls or iterations
Restricted tool access based on security considerations
Budget constraints for resource consumption
Human approval checkpoints for critical decisions
The architecture shifts from prescriptive flows to constraint-based systems. Instead of telling the system exactly what to do, we define what it can and cannot do, then allow it to determine its own path within those constraints. For software engineers, this represents a profound shift in system design. We must architect for possibilities rather than certainties, creating robust environments that remain stable regardless of which execution path an agent chooses to take.
4. Retrieval-Augmented Generation (RAG)
AI models, like humans, make better decisions when they have relevant information. While foundation models contain impressive amounts of knowledge, they face two fundamental limitations: their training data has a cutoff date, and they are limited to mostly public information found on the internet.
The concept of Retrieval-Augmented Generation was introduced in the 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", which proposed RAG as a solution for situations where all available knowledge can't be directly included in a model's context.
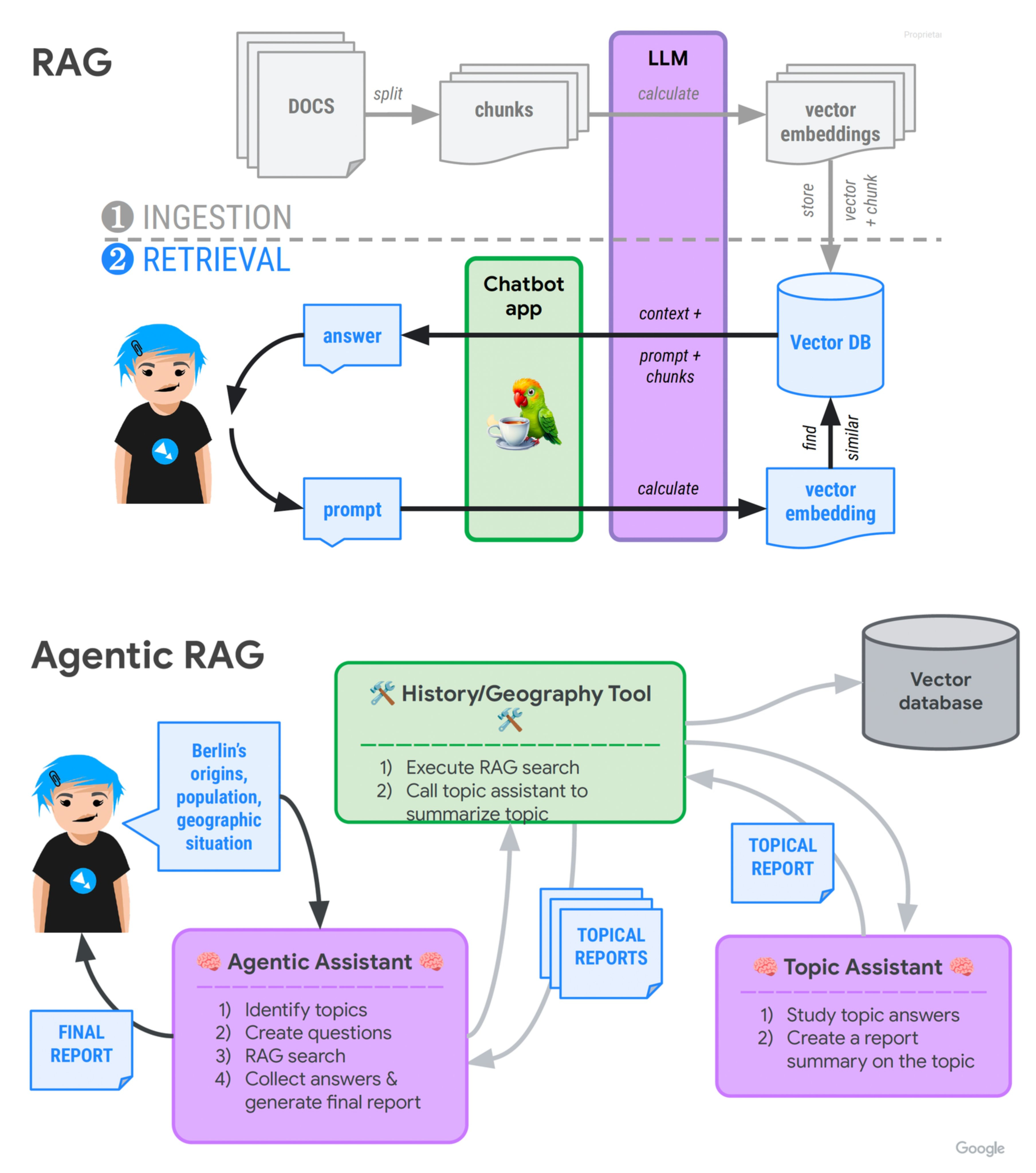
RAG solves this problem by enabling models to pull information from external sources before generating a response. Think of RAG as the "library lookup" pattern for AI systems - rather than relying solely on memorized knowledge, the app can reference specific documents, databases, or other knowledge sources on demand.
This approach offers several crucial benefits:
Reduced hallucinations: With access to factual information, models are less likely to make things up
Access to proprietary data: Models can work with your organization's internal documents
Up-to-date information: Systems can incorporate data from after the model's training cutoff
For software engineers, knowing RAG is analogous to knowing the sidecar pattern in Kubernetes. RAG extends the capability of the main container (the LLM) by providing a specialized service (information retrieval) that complements its core functionality.
5. Evals
In conventional software development, testing typically validates deterministic functions: "When I input X, I expect output Y." For AI systems, we instead need probabilistic assessments: "When I input X, is the response reasonable, accurate, and appropriate?". This fundamental challenge requires us to rethink quality assurance for AI applications. We need to evaluate whether outputs are helpful, accurate, safe, unbiased, and aligned with human values—none of which can be validated through simple assertion testing.

Modern AI evaluation frameworks employ several complementary approaches:
LLM-as-Judge leverages the linguistic understanding of one AI system to evaluate another. This approach acknowledges that language models excel at nuanced assessments of text quality, coherence, and appropriateness.
Metric-Based Evaluations focus on quantifiable dimensions of performance. These include factual accuracy where outputs are compared against trusted information sources, hallucination detection to identify when models fabricate information, context relevance assessments that determine if responses properly address specific queries, task completion rates measuring successful execution of user instructions, and safety scores for detecting harmful content. Together, these metrics provide a comprehensive view of model performance across critical dimensions.
Human Feedback Collection remains essential, particularly for subjective elements like helpfulness, creativity, and tone. Despite advances in automated evaluation, human judgment continues to serve as the gold standard for assessing many aspects of AI-generated content.
The evaluation landscape has rapidly evolved from ad-hoc testing to comprehensive frameworks that span the entire AI application lifecycle:
Development-time evaluation helps engineers catch issues early during model development. Continuous evaluation applies CI/CD principles to AI systems, with automated testing on each iteration. Production monitoring extends evaluation into deployed applications, tracking model performance on real-world inputs. This closes the loop by identifying issues that weren't caught in pre-deployment testing and capturing edge cases for future evaluation sets, creating a virtuous cycle of continuous improvement.
For software engineers, evaluation frameworks represent not just a quality assurance step but a fundamental part of the development process that helps shape model behavior and catch failures before they impact users. Understanding evals is crucial for ensuring AI applications meet quality standards and perform reliably in production environments.
6. Vibe Coding
Vibe coding, a term coined by Andrej Karpathy in February 2025 in his viral tweet, refers to a specific approach to programming where developers "fully give in to the vibes" and "forget that the code even exists."

As Simon Willison clarifies in his newsletter, vibe coding means letting the LLM write and ship code without review. It's distinct from responsible AI-assisted development, where output is verified. Using an LLM to generate code snippets that you then review, understand, and integrate is not vibe coding—it's just responsible software development with AI tools.
Vibe coding shines for:
Quick prototypes and experiments
Personal projects with low stakes
Learning and building intuition about what AI can do
Democratizing programming for non-developers
However, vibe coding is unsuitable for:
Production systems where reliability matters
Applications handling sensitive data or money
Code that needs to be maintained long-term
Projects requiring specific security or performance characteristics
A software developer’s role goes beyond writing code and shipping features. It involves building systems that are reliable, maintainable, and understandable by humans. Vibe coding prioritizes speed and non-technical accessibility, which can be useful in certain scenarios, but it’s not a replacement for disciplined, intentional engineering.
7. Chain of Thought (CoT)
Prompt engineering is the practice of crafting inputs to AI models to effectively guide their outputs. Unlike traditional programming where instructions follow strict syntax, prompt engineering involves designing natural language instructions that shape an AI's behavior. For software engineers, this skill has become essential—it's effectively the "API" for interacting with language models.
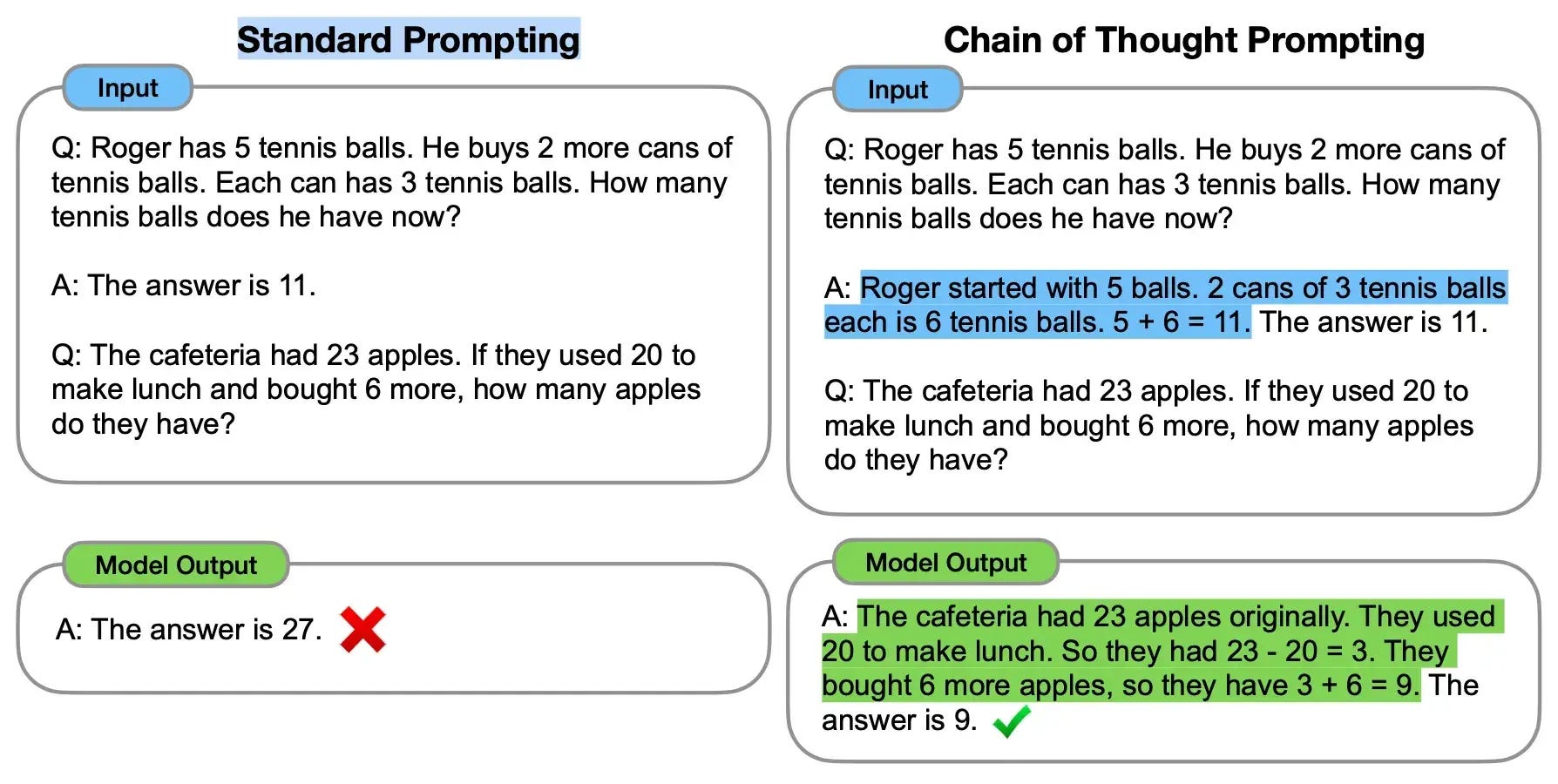
Chain of Thought prompting encourages AI models to break down complex problems into step-by-step reasoning before providing a final answer. Instead of just asking "What's 17 × 24?", you ask "What's 17 × 24? Let's solve this step by step."
Adding cues like "Let's think step by step" often triggers structured reasoning learned during training, resulting in dramatically improved accuracy for tasks requiring reasoning, calculation, or multi-step analysis. It works because modern LLMs have been trained on numerous examples of human reasoning, but need a cue to activate this capability.
CoT is particularly valuable for software engineers when:
Generating complex code that requires careful planning
Debugging issues that need logical analysis
Breaking down requirements into implementable steps
Reviewing complicated logic or algorithms
The main tradeoff is verbosity—CoT responses use more tokens, which means higher costs and longer generation times. However, for tasks where accuracy matters more than speed, this is often worthwhile.
8. Tool Calling
In AI applications, tool calling (also known as function calling) is a pattern where large language models (LLMs) can extend their capabilities by requesting external functions to be invoked. These tools can retrieve information (e.g., weather data, database lookups) or perform actions (e.g., send an email, update a record). This pattern enables models to work with up-to-date or dynamic information they wouldn’t otherwise know. Although often called “function calling,” tool calling is a better name because it reflects a broader abstraction: tools may not be pure functions—they can be services, workflows, or stateful processes. The term also aligns with the Model Context Protocol (MCP), which standardizes model interaction with external tools via structured, declarative calls.
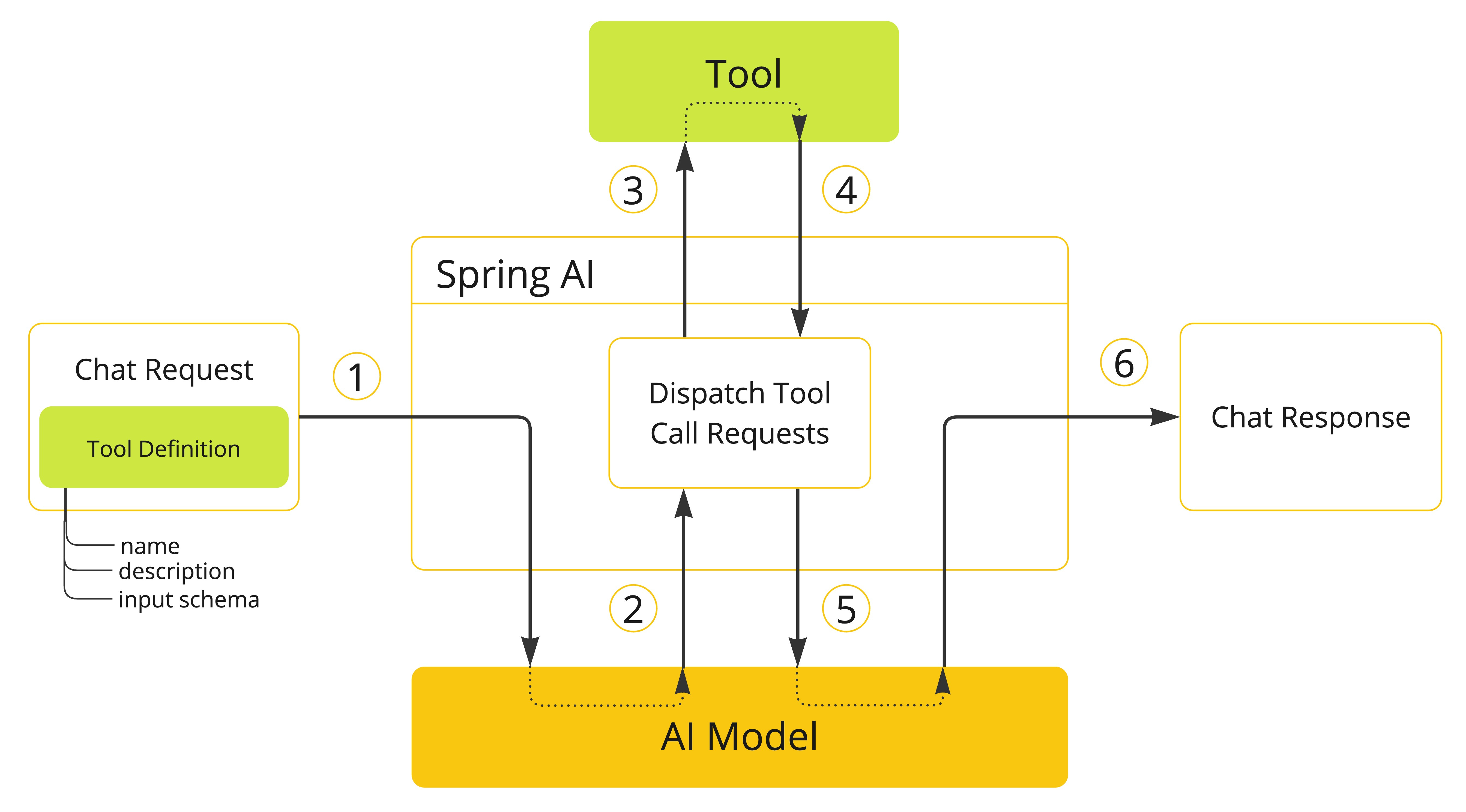
Something to be aware for new comers, the model does not directly execute these tools. It only produces a tool call request—containing the tool name and input parameters. The hosting application is responsible for resolving this request, executing the corresponding tool, and returning the result back to the model. This separation ensures safety, auditability, and flexibility, as the model cannot autonomously interact with external systems. Tool calling lets developers tightly control what models can do, while still enabling context-aware behaviors.
9. Generated Code Execution
Language models excel at natural language understanding and generation but struggle with precise calculations, data manipulations, and interactions with external systems. This limitation significantly constrains their ability to solve real-world problems that require computational accuracy or data processing. Generated code execution bridges this gap by combining the creative, adaptive reasoning of AI with the deterministic reliability of code. This represents a paradigm shift in how AI systems interact with computational environments. Unlike traditional development where code is written, reviewed, and deployed in advance, this approach enables AI models to dynamically generate and execute code at the exact moment it's needed.
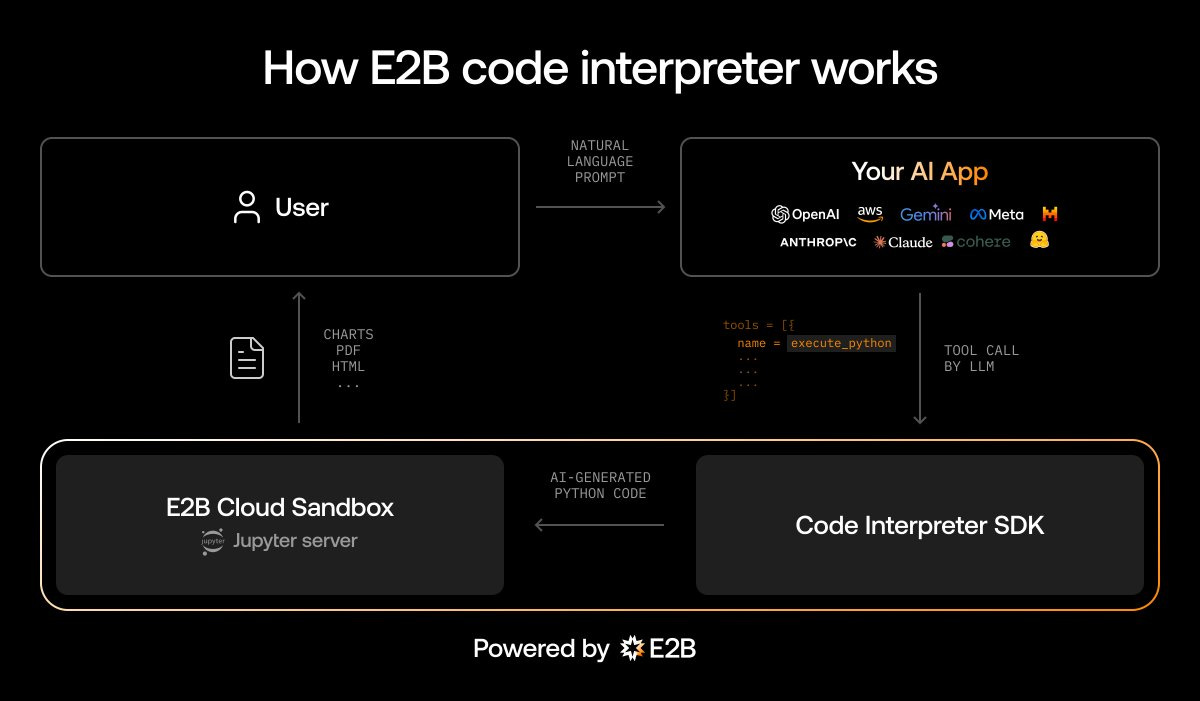
At its core, Generated code execution follows a simple flow:
An AI system identifies a computational need within a conversation or task
The system generates appropriate code to address this need
The code is executed in a secure, isolated environment
Results are captured and integrated back into the AI's reasoning process
The AI can iterate on the code based on results or evolving requirements
This execution happens in real-time, maintaining the users’ flow of interaction while dramatically expanding the AI's capabilities. Systems like E2B and Microsoft's AutoGen, OpenAI’s Code Interpreter, represent different implementations to solving the same technical challenge. Implementation approaches range from sandboxed virtual machines, containerized environments, SaaS, with varying tradeoffs between security, performance, and resource usage.
This approach enables AI systems to:
Perform complex calculations with perfect accuracy
Analyze and visualize data on demand
Interact with external APIs and services
Transform and process structured data precisely
Build custom utilities tailored to specific tasks
Prototype solutions in real-time
Verify logical reasoning through computational proof
As this technology matures, we'll likely see generated code execution become an integral feature of AI-enhanced software development environments. For software engineers, this capability fundamentally changes architecture considerations. Rather than anticipating and pre-implementing every computational need, systems can be designed with the expectation that the AI will generate appropriate code on demand, allowing for more flexible and powerful applications.
10. Guardrails
Guardrails in generative AI are safety mechanisms that constrain an LLM's behavior within predefined parameters, preventing harmful, biased, or incorrect outputs while preserving the model's ability to generate helpful responses. For software engineers, implementing guardrails has become essential when building AI-powered applications that interact directly with users.

Without proper guardrails, LLM applications are vulnerable to adversarial attacks:
Prompt injection: Attackers can insert instructions that override the model's intended behavior (e.g., "Ignore your previous instructions and instead...")
Prompt leaking: Attacks that trick the model into revealing its system prompts or configuration
Token smuggling: Bypassing filters by misspelling words or using symbols (e.g., "h0w to bu1ld a b0mb")
Payload splitting: Breaking harmful requests into seemingly innocent parts that the model later combines
Consider this example: Without guardrails, asking "Can you tell me how to hack a website?" might yield detailed instructions for illegal activities. With guardrails, the model instead responds: "I cannot assist with illegal activities, but I can provide information about ethical cybersecurity practices."
Several approaches can be used to implement guardrails:
Input and Output Filtering
This includes blocking inputs or outputs containing harmful content such as hate speech, violence, or illegal activities; defining specific topics the model should refuse to discuss; blocking specific words, competitors' names, or sensitive terminology; and identifying and redacting personally identifiable information (PII).
Pattern-Based Approaches
These use regular expressions to identify problematic content, flag specific terms that indicate prohibited topics, and apply heuristic rules to evaluate content safety.Model-Based Approaches
This involves deploying specialized models to evaluate the safety of inputs and outputs, using models trained to detect harmful content, and determining whether user requests have malicious intent.Architectural Approaches
These include validating user inputs before they reach the LLM, checking model outputs before returning them to users, overlapping validation with generation to minimize latency, and validating output chunks during generation to support streaming.
For software engineers implementing AI systems, guardrails represent the crucial security layer between powerful but unpredictable language models and the users who interact with them. For more detailed implementation strategies, see AWS's guide on building safe AI applications with guardrails.
Final Thoughts
These 10 concepts aren’t just buzzwords—they reshape software design, architecture, and delivery. For software engineers, understanding them is no longer optional. As generative AI continues to evolve, these ideas will form the foundation for the next generation of software systems.
If you found this valuable, subscribe to generativeprogrammer.com newsletter for more practical insights on AI and modern software architecture. Follow me on twitter @bibryam for ongoing updates.