

Distribution vs Escalation: When to Use Subagents or Advisors
Two patterns for scaling a Claude agent. Both add a second model to the loop, each with different trade offs. Here’s when to reach for each, and when to use both.
The one-line difference
> Subagents isolate context. Advisors unblock execution.
Both patterns add a second model inside a Claude agent, each with different strengths. A subagent takes a piece of the work off the main agent’s hands and runs it in its own context window. An advisor never touches the work. It reads the shared transcript and returns guidance on what to do next. One scales throughput and context. The other scales judgment.
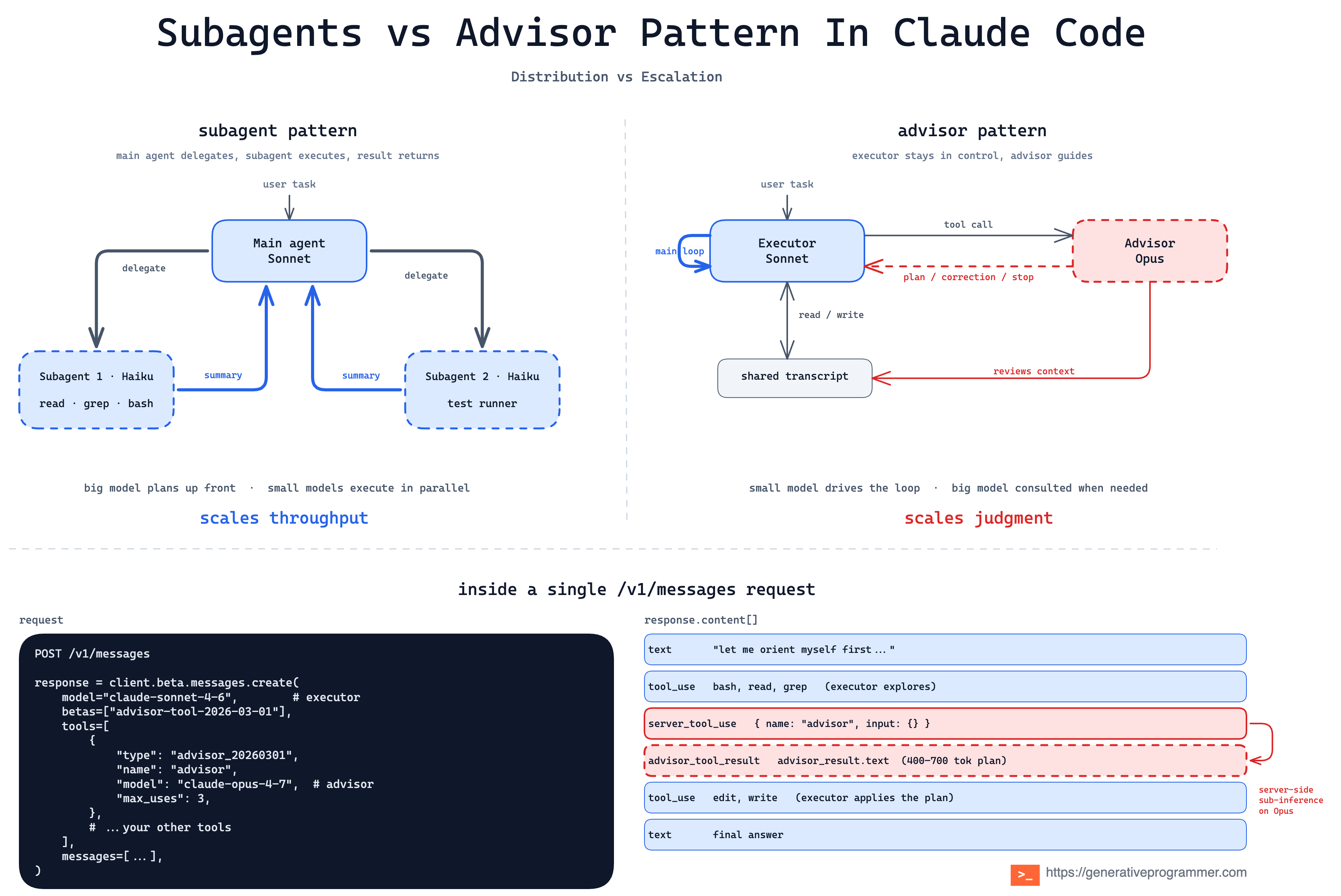
Left: a main agent delegates a scoped task to a subagent, which runs independently and returns a result. Right: an executor stays in control and consults a stronger advisor when it hits a decision it can’t reasonably solve.
The subagent pattern
In one line. A main agent delegates a scoped task to a separate subagent, which runs independently in its own context window and returns a result.
Subagents are defined in Markdown files with YAML frontmatter, stored in .claude/agents/ (project) or ~/.claude/agents/ (user). Each one runs in its own context window with a custom system prompt, specific tool access, and independent permissions. When Claude encounters a task that matches a subagent’s description, it delegates, the subagent works independently, and the summary returns to the parent conversation.
The docs are direct on when to reach for one: “a side task would flood your main conversation with search results, logs, or file contents you won’t reference again.” Running tests, fetching documentation, processing log files. The verbose output stays in the subagent’s context; only the relevant summary comes back.
You can restrict tools with an allowlist or denylist, pick the model (sonnet, opus, haiku, or inherit), set permission modes, scope MCP servers, attach skills, enable persistent memory, run in an isolated git worktree. Claude Code ships with three built-in subagents: Explore (Haiku, read-only, for codebase search), Plan (read-only, for plan mode), and general-purpose (all tools).
One structural constraint: subagents cannot spawn other subagents as nested delegation is not supported. If you need it, the docs point at skills or chaining subagents from the main conversation.
There are two flavors of subagents: fresh-start vs forked.
The default subagent starts with empty context.
A forked subagent, behind the experimental
CLAUDE_CODE_FORK_SUBAGENT=1flag, inherits the parent’s full transcript, system prompt, tools, and model instead. Tool calls still stay out of the parent’s view and only the final result returns, so the context-window benefit holds. Because the system prompt and tool definitions match the parent, the first request reuses the parent’s prompt cache, which makes a fork cheaper than a fresh subagent for context-heavy side work. Reach for forked subagents when re-explaining the situation to a fresh subagent would cost more than it saves, or when you want to try several approaches in parallel from the same starting point.
The main trade-off. A default subagent starts fresh, trading conversation continuity for isolation and tool restrictions. A fork keeps the continuity but gives up the ability to swap models, restrict tools, or override the system prompt. In both cases, returns add back to the main context window, so running many subagents that each return detailed results can re-flood the context you were trying to keep clean.
The advisor pattern
In one line. A faster and cheaper executor (Sonnet or Haiku) consults a stronger advisor (Opus) model mid-generation, inside a single /v1/messages request.
The advisor tool ships as advisor_20260301 on the Claude Platform. You declare it alongside your other tools in the Messages API, and the executor decides when to invoke it. The advisor never calls tools or produces user-facing output. It reads the shared transcript, returns a plan, a correction, or a stop signal, and the executor resumes.
The handoff is a server-side sub-inference inside one /v1/messages request. No extra round-trips. Advisor responses are short, typically 400 to 700 text tokens, and max_uses caps them per request. Executor and advisor tokens bill at their own rates, so the overall run costs well below running the advisor model end-to-end.
In Anthropic’s evaluations, Sonnet with an Opus advisor gained 2.7 percentage points on SWE-bench Multilingual and reduced cost per task by 11.9%. The framing is deliberate: the advisor strategy “inverts a common sub-agent pattern, where a larger orchestrator model decomposes work and delegates to smaller worker models.” Here, the smaller model drives and escalates. Frontier reasoning applies only when the executor needs it.
The pattern has academic precedent. UC Berkeley researchers formalised it in late 2025 as “advisor models”: small policies trained to generate per-instance natural-language steering for larger black-box models. The paper found that advice generalises across model families (advisors trained on GPT transferred to Claude without retraining), which is why this is an architecture pattern, not a Claude feature. Anthropic’s contribution is making it a one-line tool declaration experience.
The main trade-off. Every escalation is a synchronous pause in the executor’s stream while the advisor runs. The advice is one-shot. No iteration, no debate. If the advisor is wrong on a specific point, the executor’s only recourse is another advisor call to reconcile, which burns more of the max_uses budget.
A decision framework
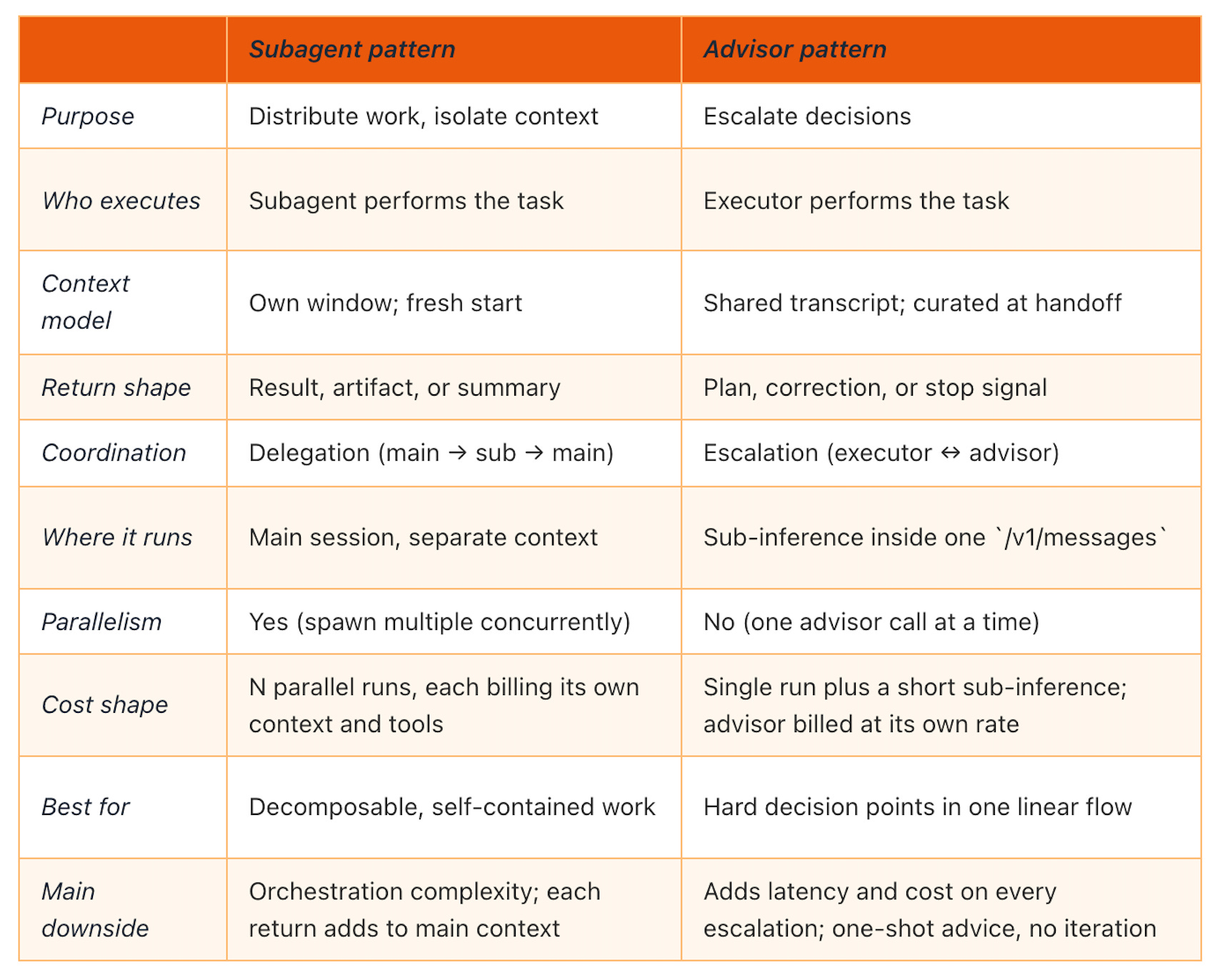
Questions separate them:
Does the work split into specialized, distinct tasks with well-defined inputs and outputs? Subagents. Distribution pays when each unit of work has a clear start, a clear end, and doesn’t need a back-and-forth conversation with the main agent in the middle.
Does the work mostly need better judgment, not more hands? Advisor. One model can usually handle a task if someone smarter checks in at the hard moments.
Is a side task about to flood the main context with output you won’t reuse? Subagent, read-only, summarize back. This is the pattern’s textbook case.
When none of these fire cleanly, the work is probably small enough to stay in the main conversation.
When to use both
The two patterns compose. A Sonnet executor can consult an Opus advisor on hard decisions and spawn Haiku subagents for bounded or parallelizable subtasks in the same run. Distribution handles breadth, escalation handles depth, and the cost shape composes too: Haiku does the cheap bulk, Opus applies frontier reasoning only where it changes the outcome, and Sonnet carries the rest.
A subagent is its own Claude run, so it can carry its own advisor too. Anthropic has only benchmarked the top-level composition publicly; treat nested advisor-inside-subagent as an op
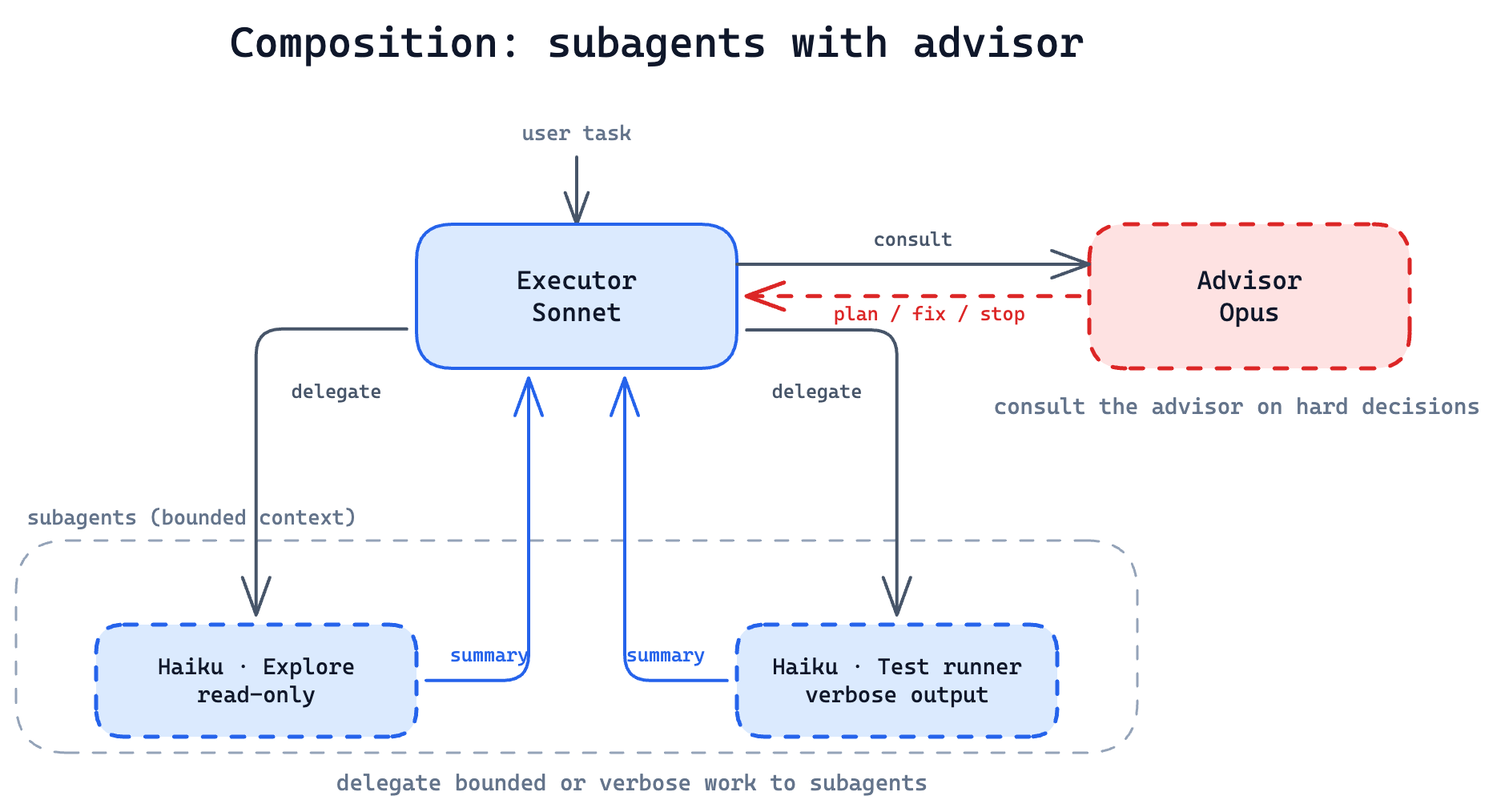
A Sonnet executor consults an Opus advisor on hard decisions and spawns Haiku subagents for bounded subtasks
One more shape: agent teams
There is also a third shape worth naming: agent teams. Use them when subagents need to talk to each other directly, not just report back to a parent. They are more experimental, more complex, and harder to reason about than either pattern here. Reach for them only when the coordination overhead is justified. For a deeper comparison between subagents and agent teams, Han HELOIR YAN’s write-up is the clearest one I’ve found.
The takeaway
Subagents break a complex task into smaller blocks, each with its own context, tools, and specialization. The advisor makes each block more autonomous: when the cheaper model hits a hard call, the stronger one is a tool call away. Together, they give you specialization plus depth, a real step toward long-horizon agent runs that a single model in a single context cannot sustain.
Sources: The advisor strategy, Anthropic, April 9, 2026. Create custom subagents, Claude Code documentation.
how about including /fork (forked subagent)? recently learned about this... worth adding as another shape so more people are aware