

Stop Babysitting Your Coding Agent. Give It Backpressure.
Backpressure is feedback that reaches the agent before the agent reaches the human.
The Backpressure Loop is becoming one of the defining patterns for successful coding agents. Agents can generate code quickly, but generation without feedback is still an open loop: the agent produces a diff, yet it cannot tell whether the diff is correct, useful, safe, or ready unless the system pushes back. Backpressure can come from a type checker, a test, a linter, a build, a browser check, logs, traces, structural rules, or evals. The source matters less than the loop: the agent sees the failure, repairs the work, and tries again.
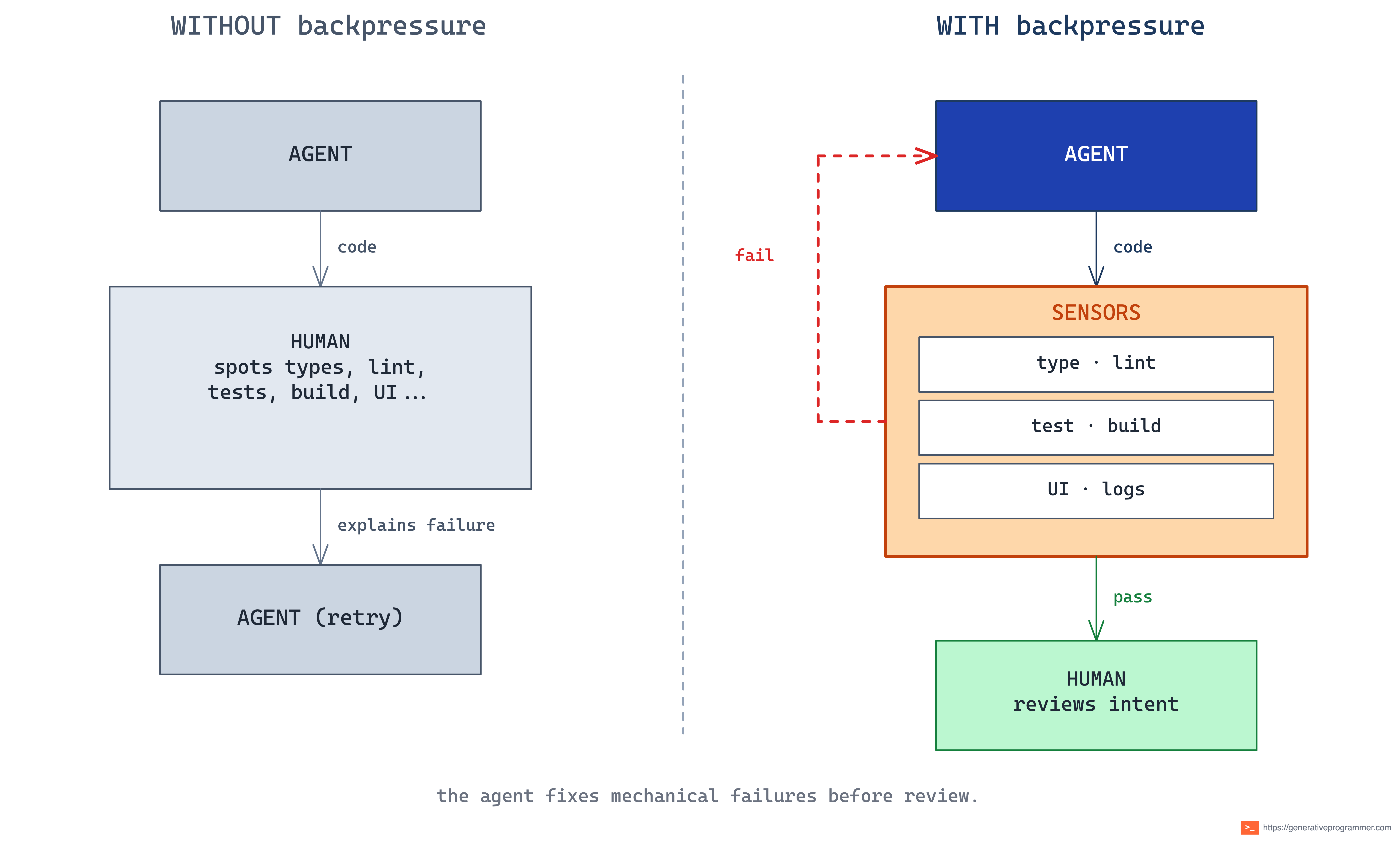
The failure mode is simple: the agent produces code faster than the engineering system can push back on bad output. Without that pushback, the human becomes the compiler, the test runner, the linter, the UI checker, and the reviewer. Every trivial mistake waits for a person to notice it, explain it, and send the agent back for another attempt.
That is not review. That is babysitting.
In Don’t waste your back pressure, Moss Banay describes this as wasted human backpressure: spending attention on mistakes the agent should have been able to detect itself, such as missing imports, broken builds, and visual errors.
I call this the Backpressure Loop Pattern.
The problem
A coding agent is a fast producer. The human reviewer is a slow consumer.
That mismatch creates pressure. If the only meaningful feedback comes from the human, every failure becomes review work. The agent writes code, the human spots a broken test, the human explains the failure, and the agent retries.
That loop does not scale.
Marc Brooker makes the deeper point in What’s Easy Now? What’s Hard Now?: agents are feedback loops around a useful but flawed model. The key shift is moving feedback from the human loop into the agent loop: build, test, inspect, repair, and iterate.
So the question is not only:
How good is the model?
The better question is:
What feedback can the agent use without asking me?
The pattern
Intent: Move cheap correctness checks out of human review and into the agent loop.
Context: A coding agent can edit files, run commands, read failures, and retry.
Problem: Agents produce code faster than humans can validate it.
Solution: Expose fast, machine-readable feedback sensors to the agent: types, tests, linters, builds, browser checks, logs, traces, and structural rules.
Result: The agent fixes mechanical failures before review. The human focuses on intent, design, and trade-offs.
What counts as backpressure
Backpressure is any signal that can push back on bad agent output before a human spends attention on it.
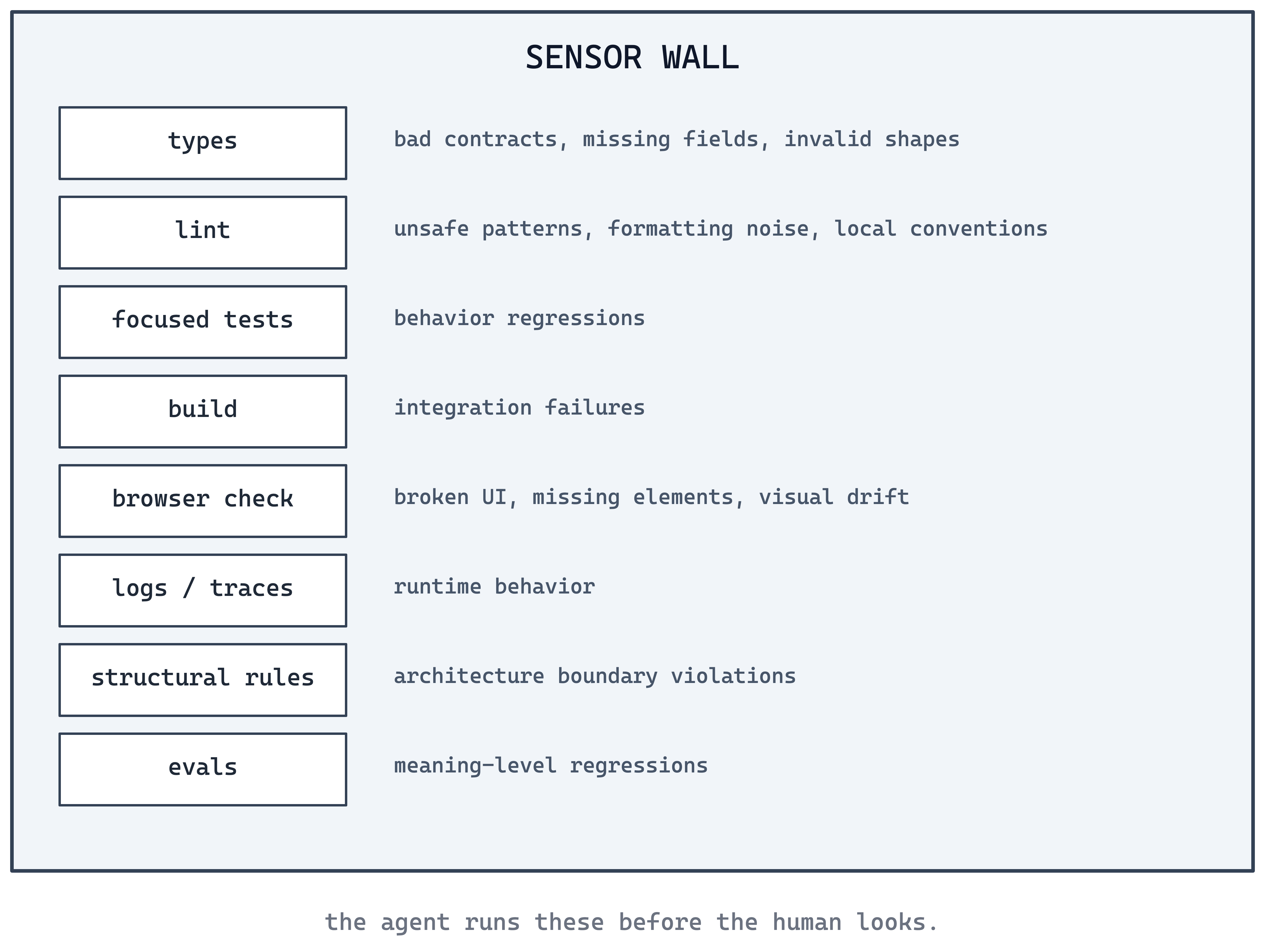
Thoughtworks calls these feedback sensors for coding agents: deterministic quality gates wired into agent workflows so failures trigger self-correction.
That distinction matters:
A CI failure after the agent is done is a gate.
A failure the agent sees while working is backpressure.
A green build is not enough
A green build is useful, but narrow.
It tells you the code compiled, the formatter ran, and the existing tests passed. It does not prove the product rule survived. It does not prove the generated test asserts meaningful behavior. It does not prove the refactor respected the architecture.
So the goal is not just “run CI earlier.”
The goal is to make feedback fast, specific, and actionable enough for the agent to repair the work.
Bad feedback:
The code is wrong.Better feedback:
auth/session.test.ts failed.
Expected expired sessions to redirect to /login.
Received 200 from /dashboard.
Fix the session expiration path.
Do not change the test.The second version gives the agent something to do.
Effective feedback beats more feedback
More output is not the same as better backpressure.
A recent arXiv preprint, Scaling Laws for Agent Harnesses via Effective Feedback Compute, makes this point in research terms. The authors argue that agent harnesses scale less with raw tokens, tool calls, wall time, or cost, and more with how efficiently they convert raw budget into useful feedback.
They call this Effective Feedback Compute: feedback that is informative, valid, non-redundant, and retained for later decisions.
That maps directly to coding agents.
A test failure is useful only if the agent can understand it, trust it, avoid repeating it, and use it to change the next attempt.
Useful backpressure has four properties:

That is why a thousand lines of logs can be worse than a short, structured failure.
The goal is not more agent activity. The goal is more effective feedback.
How to implement it
Start with the boring checks.
Put the exact commands in AGENTS.md, CLAUDE.md, or the equivalent project instruction file:
After changing TypeScript:
- run npm run typecheck
- run npm run lint
- run npm test -- --changed
- fix failures before opening a PRThen make the output efficient.
Do not dump hundreds of lines of passing test output into the agent context. Passing checks should be tiny. Failing checks should show the useful detail.
HumanLayer describes this as context-efficient backpressure: replace passing test, build, and lint output with a small success signal, but expose full output when a command fails.
Example:
✓ typecheck
✓ lint
✗ auth tests
FAIL auth/session.test.ts
Expected redirect to /login for expired session.
Received 200 from /dashboard.That is enough signal for the agent to continue.
The rule:
Success should be compressed. Failure should be actionable.
The trade-off
Backpressure is not free.
Fast sensors improve flow, but slow sensors choke it.
Do not put every possible check inside the inner loop. Layer them.
In session:
typecheck, lint, focused tests, build, screenshots
Before PR:
full tests, integration tests, structural rules, security checks
Scheduled or explicit:
mutation testing, fuzzing, semantic evals, architecture drift reviewBirgitta Böckeler’s Maintainability sensors for coding agents is useful here because it separates sensors that run during the coding session from sensors that belong in the pipeline, on a schedule, or in production.

That is the right mental model: not every check belongs in the same loop.
The inner loop should be fast enough that the agent can run it repeatedly. Slower checks belong outside the session unless the task is risky enough to justify the cost.
The rule
When you correct the same agent mistake twice, turn it into backpressure.
A test.
A type.
A linter rule.
A build check.
A browser assertion.
A better error message.
A small script the agent can run before it asks for review.
The future skill is not asking agents to try harder.
It is designing feedback loops that make bad output harder to accept.