

Applying Kubernetes Patterns to LLM Workloads
How the patterns you already know carry over to LLMs, with a few important twists.
A few years ago, Roland Huss and I wrote Kubernetes Patterns, a catalogue of repeatable solutions for building cloud-native applications on Kubernetes. The book covers patterns across six categories: foundational, behavioral, structural, configuration, security, and advanced, everything from health probes and init containers to controllers, operators, and elastic scaling. Recently, Roland and Daniele Zonca co-authored a new book, Generative AI on Kubernetes, which covers the operational side of running LLMs on Kubernetes. I was a reviewer on that book, and the more I read through it, the more I recognized patterns from our original work, just applied to a very different class of workload. Deployments, StatefulSets, Init Containers, DaemonSets. They were all there. Just with bigger numbers.
Here is a high-level summary of how Kubernetes patterns apply to LLM workloads, which Roland and I will cover in more detail in our upcoming KubeCon + CloudNativeCon Europe 2026 talk in Amsterdam.
Same Kubernetes, Different Workload
A typical cloud-native application on Kubernetes follows a well-known stack.
An Ingress routes HTTP traffic to stateless App Pods managed by a Deployment.
An init container runs database migrations before the app starts.
PostgreSQL runs as a StatefulSet with persistent storage.
A CronJob generates reports on a schedule.
A layer of DaemonSets, such as Prometheus Node Exporter and Fluentd, provides
That is six Kubernetes patterns at work: Controller, Stateless Service, Init Container, Stateful Service, Batch Job, Daemon Service.
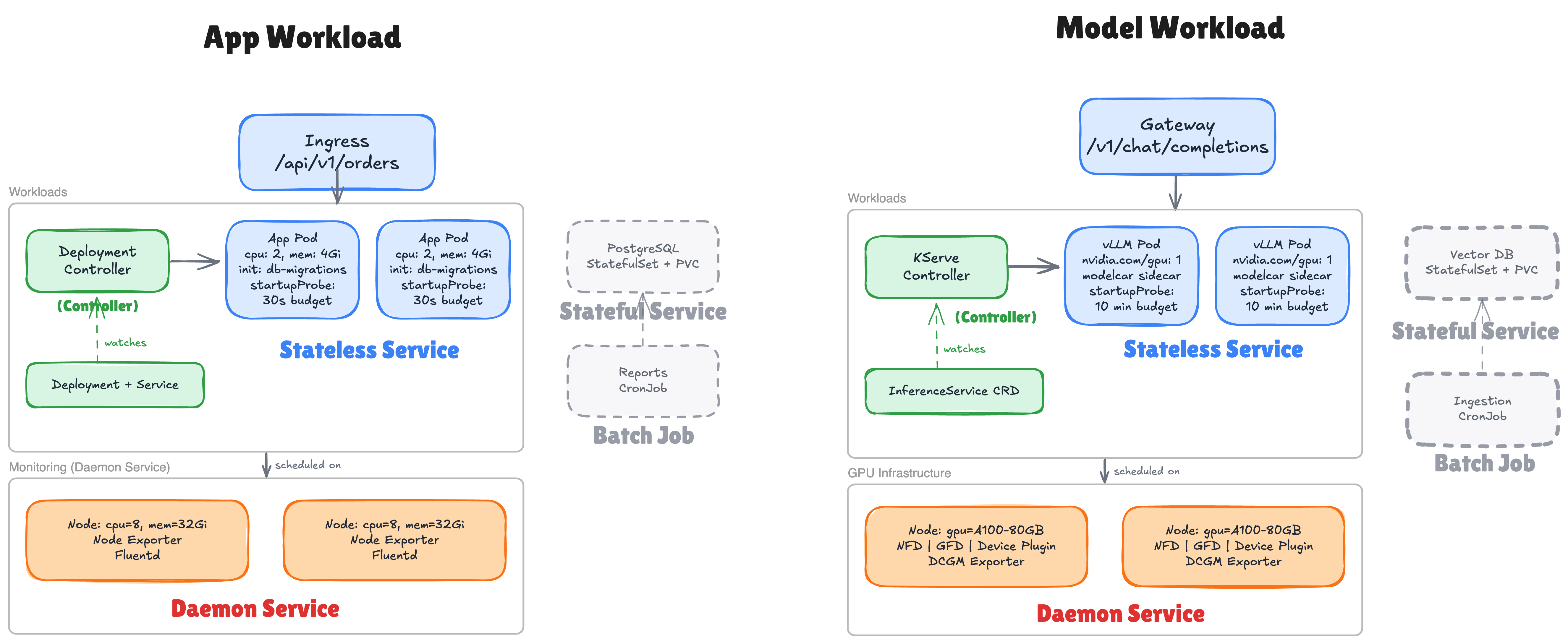
An LLM workload uses the same patterns, but is a fundamentally different kind of workload.
A model is not an application binary. It is tens to hundreds of gigabytes of learned parameters, read-only data that must be loaded into GPU memory before a server can handle a single request. Meta’s Llama 70B weighs around 140 GB in full precision (FP16), or 35–40 GB with 4-bit quantization. Loading takes minutes, not seconds.
It requires specific hardware: a node with the right GPU, enough VRAM (Video RAM, the memory on the GPU where weights and intermediate computations live), and sometimes a specific GPU interconnect topology.
Initialization looks different too. In a traditional app, an init container fetches a config file or runs a migration, a few megabytes, done in seconds. In an LLM stack, the equivalent step stages tens to hundreds of gigabytes of model weights. Once the weights are in place, the model server (vLLM, TGI) goes through a multi-phase startup: loading weights into GPU VRAM, compiling CUDA graphs, and pre-allocating the KV cache (the memory region where the model stores computed attention states so it doesn’t recompute them for every new token). This takes minutes. Your startup probe needs
failureThreshold: 60withperiodSeconds: 10, a 10-minute budget.The request profile differs too. In a traditional web service, requests have roughly uniform cost. Round-robin load balancing works. LLM inference breaks this assumption: a 10-token request completes in 200 ms while a 4,000-token request occupies a GPU for 30 seconds. Both arrive as identical
POST /v1/chat/completionsrequests. Round-robin creates hot spots.Scaling signals break down. Out-of-the-box HPA on CPU is not a good fit for GPU inference workloads. You need scaling on LLM-specific metrics: token queue depth (
vllm:num_requests_waiting), time-to-first-token, KV cache utilization.Scale-to-zero is impractical when model loading takes five minutes.
The infrastructure layer changes. Where you had Node Exporter and Fluentd, you now run NFD (Node Feature Discovery) to label hardware, GFD (GPU Feature Discovery) to add GPU model and VRAM labels, the NVIDIA device plugin to expose
nvidia.com/gpuas a schedulable resource, and the DCGM exporter (Data Center GPU Manager) to feed GPU metrics to Prometheus. That is your new stack of DaemonSets forming the GPU infrastructure layer.
Projects like KServe (incubating at CNCF) address these by applying the Controller pattern to model serving. You write an InferenceService CRD, declare the model, the runtime, the scaling policy, and KServe reconciles: Deployment, Service, storage initializer, startup probes, GPU scheduling.
Despite all this, the fundamentals are the same. Controller, Stateless Service, Init Container, Stateful Service, Batch Job, Daemon Service, all present. The parameters changed, but the patterns held.
What stays the same in GenAI on Kubernetes
Many Kubernetes patterns apply to LLM workloads without fundamental modification. The pattern works as-is, you only point it at a different workload.
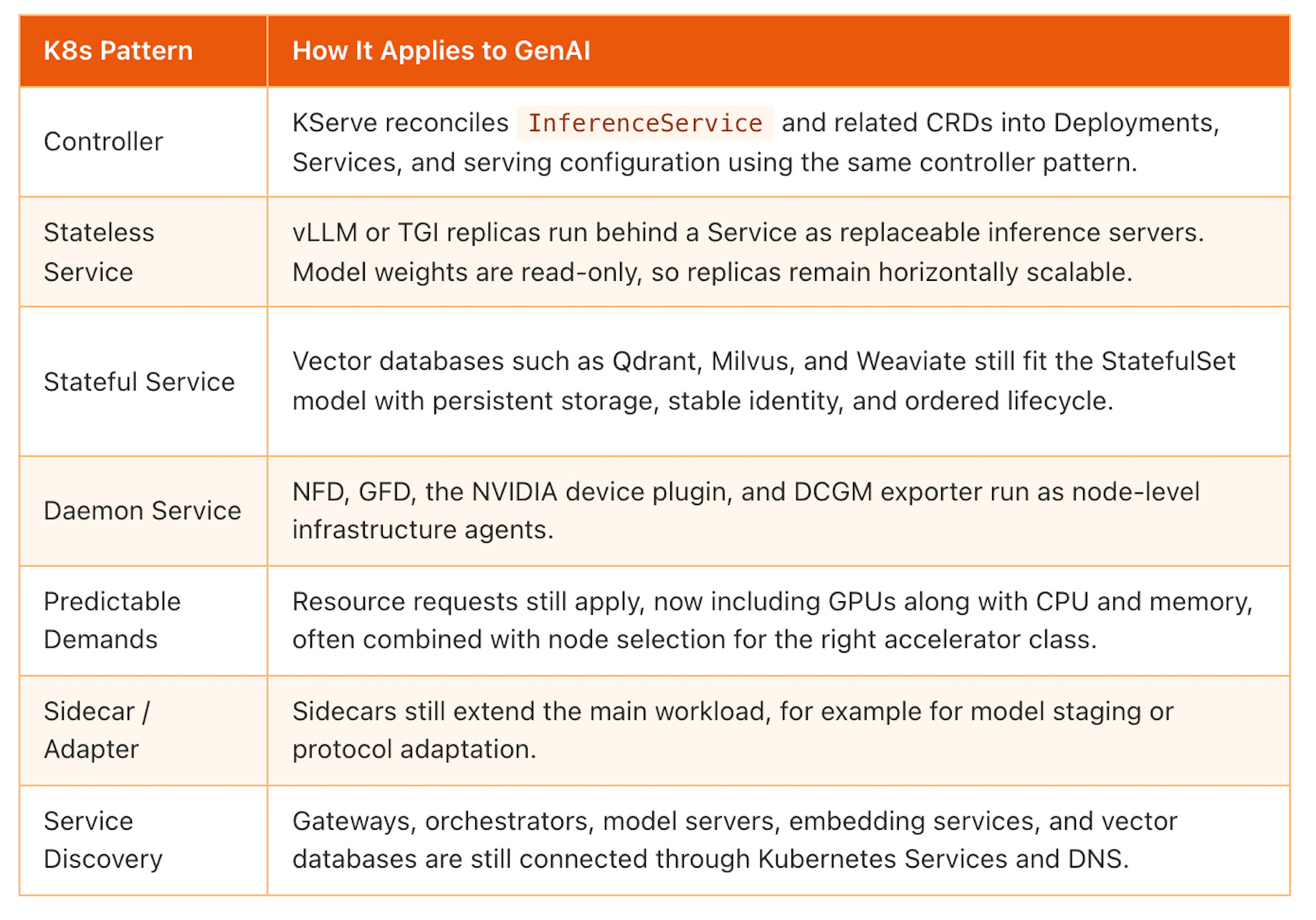
These are the direct mappings. The Kubernetes primitive stays the same, but the workload behind it changes from web apps and databases to model servers, vector databases, and GPU infrastructure.
What changes in GenAI on Kubernetes
These patterns still apply to GenAI, but something fundamental changes about how they work. The pattern skeleton is the same; the parameters, scale, or semantics push them beyond their original design.
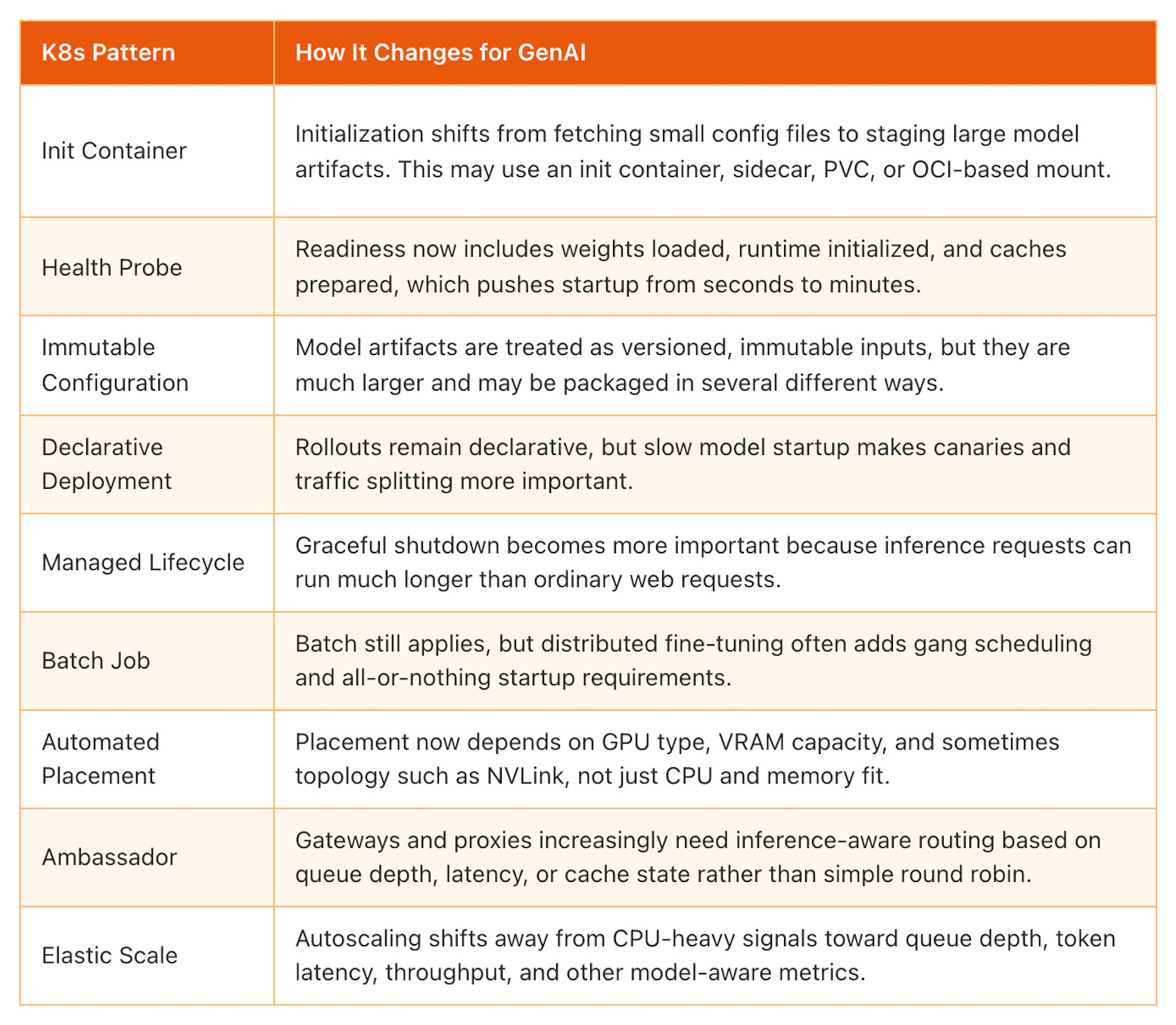
This is where LLM workloads start to stretch familiar Kubernetes patterns. The abstraction still holds, but the operational reality changes. Seconds become minutes. Megabytes become gigabytes. CPU-centric assumptions stop working.
Emerging Patterns for AI Workloads
Some patterns do not have clear ancestors in the Kubernetes pattern catalogue. They emerge from the specific characteristics of LLM workloads.
Model Data Staging addresses the challenge of delivering hundreds of gigabytes of model weights to Pods without turning every scale-up into a multi-minute outage.
Token-Aware Routing replaces round-robin with metric-driven endpoint selection based on queue depth and KV cache state. This is being implemented through the Gateway API Inference Extension and projects like llm-d.
RAG Composition wires together four distinct workload types into a coherent application: the orchestrator, the LLM, the vector database, and the ingestion pipeline. Each maps to its natural Kubernetes primitive.
Disaggregated Serving separates the compute-intensive prefill phase from the memory-intensive decode phase, runs them on different hardware, and lets them scale independently. Projects like llm-d are enabling this model.
Agentic Workflows introduce LLM agents that plan, use tools, and iterate. They are also driving new protocols such as MCP (Model Context Protocol) for agent-to-tool integration and A2A (Agent-to-Agent Protocol) for inter-agent communication.

Building Production-Ready Agent Systems with MCP Something related: Our friends at Deep Engineering are hosting a workshop, Building MCP Servers in Production, with Peder Holdgaard Pedersen. If you are exploring MCP beyond demos and into real production systems, this is worth a look, register here.

These patterns are covered in depth in Roland and Daniele’s book Generative AI on Kubernetes. Roland and I will be walking through three of them: Model Data Staging, Token-Aware Routing, and RAG Composition at KubeCon Amsterdam this week.
If you’d like more posts like this on Kubernetes, cloud-native patterns, and how they intersect with AI workloads, subscribe to my newsletter.